Machine Learning and Data Engineering

MLDE Group (2024)
The Machine Learning and Data Engineering (MLDE) group focuses on developing efficient and scalable implementations of modern machine learning methods. Our research addresses key challenges such as reducing the computational resources required for the inference phase of large-scale deep learning models or accelerating training through distributed computing. Beyond advancing algorithms, we place a strong emphasis on bridging the gap between theory and practice by designing solutions that can be deployed in real-world, resource-constrained environments. This often involves close collaboration with experts from other domains, including large-scale satellite data analysis or modern energy systems. The group is part of the Department of Information Systems of the University of Münster and is led by Fabian Gieseke.
Selected Publications
-
 N. Herrmann, J. Stenkamp, B. Karic, S. Oehmcke, and F. GiesekeICLR26 The Fourteenth International Conference on Learning Representations 2026
N. Herrmann, J. Stenkamp, B. Karic, S. Oehmcke, and F. GiesekeICLR26 The Fourteenth International Conference on Learning Representations 2026Deploying machine learning models on compute-constrained devices has become a key building block of modern IoT applications. In this work, we present a compression scheme for boosted decision trees, addressing the growing need for lightweight machine learning models. Specifically, we provide techniques for training compact boosted decision tree ensembles that exhibit a reduced memory footprint by rewarding, among other things, the reuse of features and thresholds during training. Our experimental evaluation shows that models achieved the same performance with a compression ratio of 4–16x compared to LightGBM models using an adapted training process and an alternative memory layout. Once deployed, the corresponding IoT devices can operate independently of constant communication or external energy supply, and, thus, autonomously, requiring only minimal computing power and energy. This capability opens the door to a wide range of IoT applications, including remote monitoring, edge analytics, and real-time decision making in isolated or power-limited environments.
@inproceedings{treesonadiet, title = {Boosted Trees on a Diet: Compact Models for Resource-Constrained Devices}, author = {Herrmann, Nina and Stenkamp, Jan and Karic, Benjamin and Oehmcke, Stefan and Gieseke, Fabian}, booktitle = {The Fourteenth International Conference on Learning Representations}, year = {2026}, tags = {ml,de,energy,rs}, projects = {tinyaiot}, url = {https://openreview.net/forum?id=batDcksZsh} } -
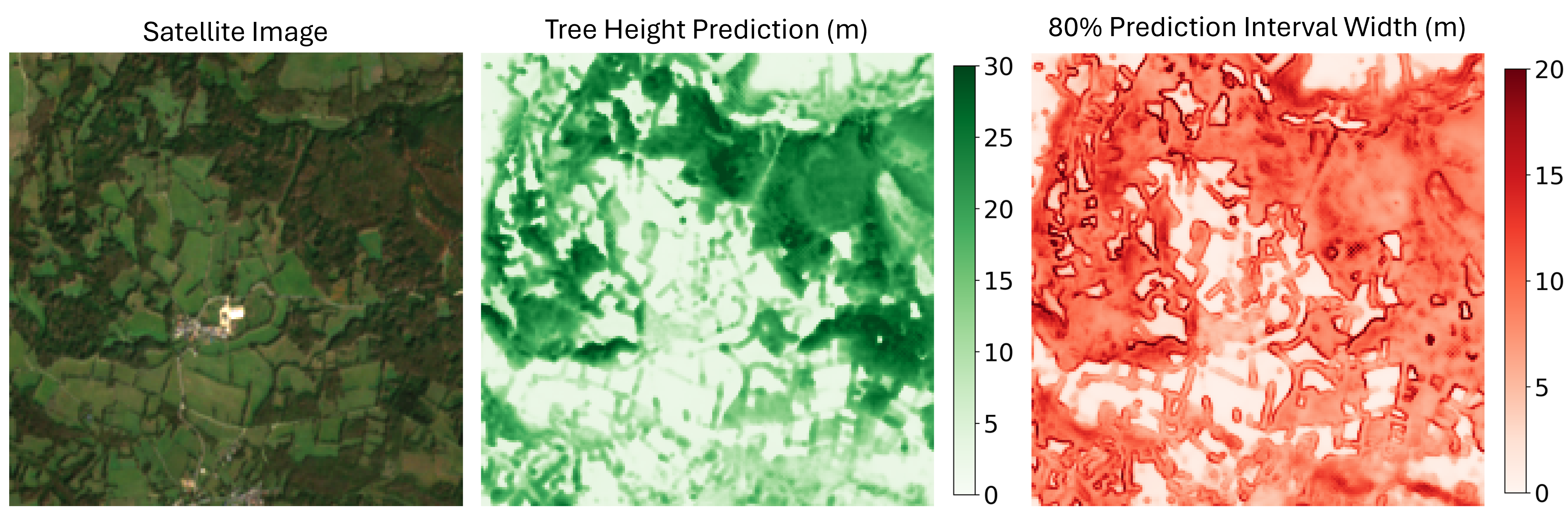 K. Schrödter, J. Pauls, and F. GiesekeAISTATS26 Twenty-Ninth Annual Conference on Artificial Intelligence and Statistics (AISTATS) 2026
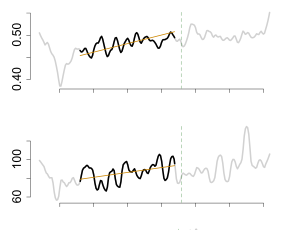
K. Schrödter, J. Pauls, and F. GiesekeAISTATS26 Twenty-Ninth Annual Conference on Artificial Intelligence and Statistics (AISTATS) 2026Accurate tree height estimation is vital for ecological monitoring and biomass assessment. We apply quantile regression to existing tree height estimation models based on satellite data to incorporate uncertainty quantification. Most current approaches on tree height estimation rely on point predictions, which limits their applicability in risk-sensitive scenarios. In this work, we show that with minor modifications to the prediction head, existing models can be adapted to provide statistically calibrated uncertainty estimates via quantile regression. Furthermore, we demonstrate how our results correlate with known challenges in remote sensing (e.g., terrain complexity, vegetation heterogeneity), indicating that the model is less confident in more challenging conditions.
@inproceedings{schroedter2026uncertaintytree, title = {Canopy Tree Height Estimation using Quantile Regression: Modeling and Evaluating Uncertainty in Remote Sensing (accepted, not yet published)}, author = {Schrödter, Karsten and Pauls, Jan and Gieseke, Fabian}, booktitle = {Twenty-Ninth Annual Conference on Artificial Intelligence and Statistics (AISTATS)}, year = {2026}, tags = {ml,application,rs}, projects = {ai4forest} } -
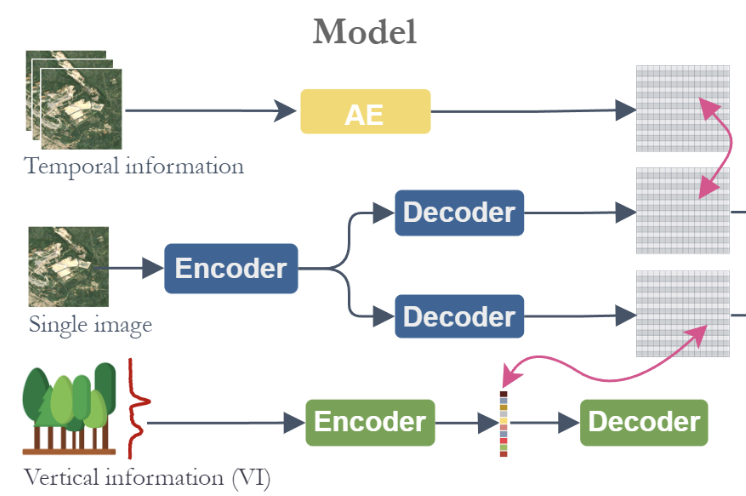 I. Fayad, M. Zimmer, M. Schwartz, P. Ciais, F. Gieseke, G. Belouze, S. Brood, A. De Truchis, and A. d’AspremontICML25 42nd International Conference on Machine Learning (ICML) 2025
I. Fayad, M. Zimmer, M. Schwartz, P. Ciais, F. Gieseke, G. Belouze, S. Brood, A. De Truchis, and A. d’AspremontICML25 42nd International Conference on Machine Learning (ICML) 2025Significant efforts have been directed towards adapting self-supervised multimodal learning for Earth observation applications. However, existing methods produce coarse patch-sized embeddings, limiting their effectiveness and integration with other modalities like LiDAR. To close this gap, we present DUNIA, an approach to learn pixel-sized embeddings through cross-modal alignment between images and full-waveform LiDAR data. As the model is trained in a contrastive manner, the embeddings can be directly leveraged in the context of a variety of environmental monitoring tasks in a zero-shot setting. In our experiments, we demonstrate the effectiveness of the embeddings for seven such tasks (canopy height mapping, fractional canopy cover, land cover mapping, tree species identification, plant area index, crop type classification, and per-pixel waveform-based vertical structure mapping). The results show that the embeddings, along with zero-shot classifiers, often outperform specialized supervised models, even in low data regimes. In the fine-tuning setting, we show strong low-shot capabilities with performances near or better than state-of-the-art on five out of six tasks.
@inproceedings{fayad2025dunia, title = {DUNIA: Pixel-Sized Embeddings via Cross-Modal Alignment for Earth Observation Applications}, author = {Fayad, Ibrahim and Zimmer, Max and Schwartz, Martin and Ciais, Philippe and Gieseke, Fabian and Belouze, Gabriel and Brood, Sarah and De Truchis, Aurelien and d'Aspremont, Alexandre}, booktitle = {42nd International Conference on Machine Learning (ICML)}, year = {2025}, tags = {ml,application}, projects = {ai4forest} } -
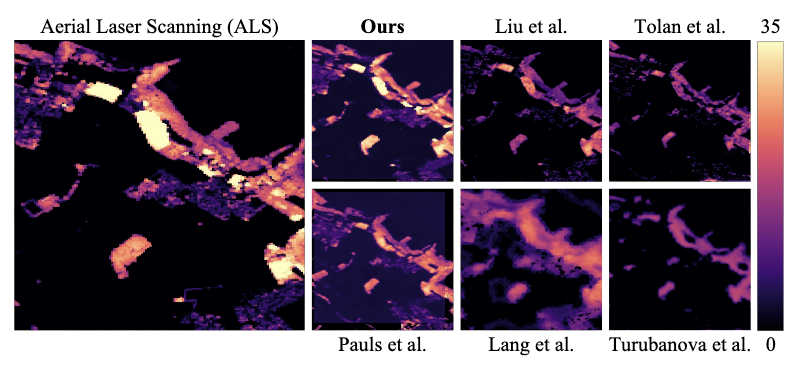 J. Pauls, M. Zimmer, B. Turan, S. Saatchi, P. Ciais, S. Pokutta, and F. GiesekeICML25 42nd International Conference on Machine Learning (ICML) 2025
J. Pauls, M. Zimmer, B. Turan, S. Saatchi, P. Ciais, S. Pokutta, and F. GiesekeICML25 42nd International Conference on Machine Learning (ICML) 2025With the rise in global greenhouse gas emissions, accurate large-scale tree canopy height maps are essential for understanding forest structure, estimating above-ground biomass, and monitoring ecological disruptions. To this end, we present a novel approach to generate large-scale, high-resolution canopy height maps over time. Our model accurately predicts canopy height over multiple years given Sentinel-2 time series satellite data. Using GEDI LiDAR data as the ground truth for training the model, we present the first 10m resolution temporal canopy height map of the European continent for the period 2019-2022. As part of this product, we also offer a detailed canopy height map for 2020, providing more precise estimates than previous studies. Our pipeline and the resulting temporal height map are publicly available, enabling comprehensive large-scale monitoring of forests and, hence, facilitating future research and ecological analyses. For an interactive viewer, see this https URL.
@inproceedings{pauls2025capturing, title = {Capturing Temporal Dynamics in Large-Scale Canopy Tree Height Estimation}, author = {Pauls, Jan and Zimmer, Max and Turan, Berkant and Saatchi, Sassan and Ciais, Philippe and Pokutta, Sebastian and Gieseke, Fabian}, booktitle = {42nd International Conference on Machine Learning (ICML)}, year = {2025}, custom = {Earth Engine|https://europetreemap.projects.earthengine.app/view/temporalcanopyheight}, tags = {ml, application}, projects = {ai4forest} } -
 P. N. Bernardino, W. D. Keersmaecker, S. Horion, R. V. D. Kerchove, S. Lhermitte, R. Fensholt, S. Oehmcke, F. Gieseke, K. V. Meerbeek, C. Abel, J. Verbesselt, and B. SomersJOURNALNature Climate Change 2025
P. N. Bernardino, W. D. Keersmaecker, S. Horion, R. V. D. Kerchove, S. Lhermitte, R. Fensholt, S. Oehmcke, F. Gieseke, K. V. Meerbeek, C. Abel, J. Verbesselt, and B. SomersJOURNALNature Climate Change 2025Climate change and human-induced land degradation threaten dryland ecosystems, vital to one-third of the global population and pivotal to inter-annual global carbon fluxes. Early warning systems are essential for guiding conservation, climate change mitigation and alleviating food insecurity in drylands. However, contemporary methods fail to provide large-scale early warnings effectively. Here we show that a machine learning-based approach can predict the probability of abrupt shifts in Sudano–Sahelian dryland vegetation functioning (75.1% accuracy; 76.6% precision) particularly where measures of resilience (temporal autocorrelation) are supplemented with proxies for vegetation and rainfall dynamics and other environmental factors. Regional-scale predictions for 2025 highlight a belt in the south of the study region with high probabilities of future shifts, largely linked to long-term rainfall trends. Our approach can provide valuable support for the conservation and sustainable use of dryland ecosystem services, particularly in the context of climate change projected drying trends.
@article{BernardinoKHKLFOGMAVS2025, author = {Bernardino, Paulo Negri and Keersmaecker, Wanda De and Horion, Stéphanie and Kerchove, Ruben Van De and Lhermitte, Stef and Fensholt, Rasmus and Oehmcke, Stefan and Gieseke, Fabian and Meerbeek, Koenraad Van and Abel, Christin and Verbesselt, Jan and Somers, Ben}, title = {Predictability of abrupt shifts in dryland ecosystem functioning}, journal = {Nature Climate Change}, year = {2025}, volume = {15}, pages = {86--91}, doi = {10.1038/s41558-024-02201-0}, tags = {application,rs}, } -
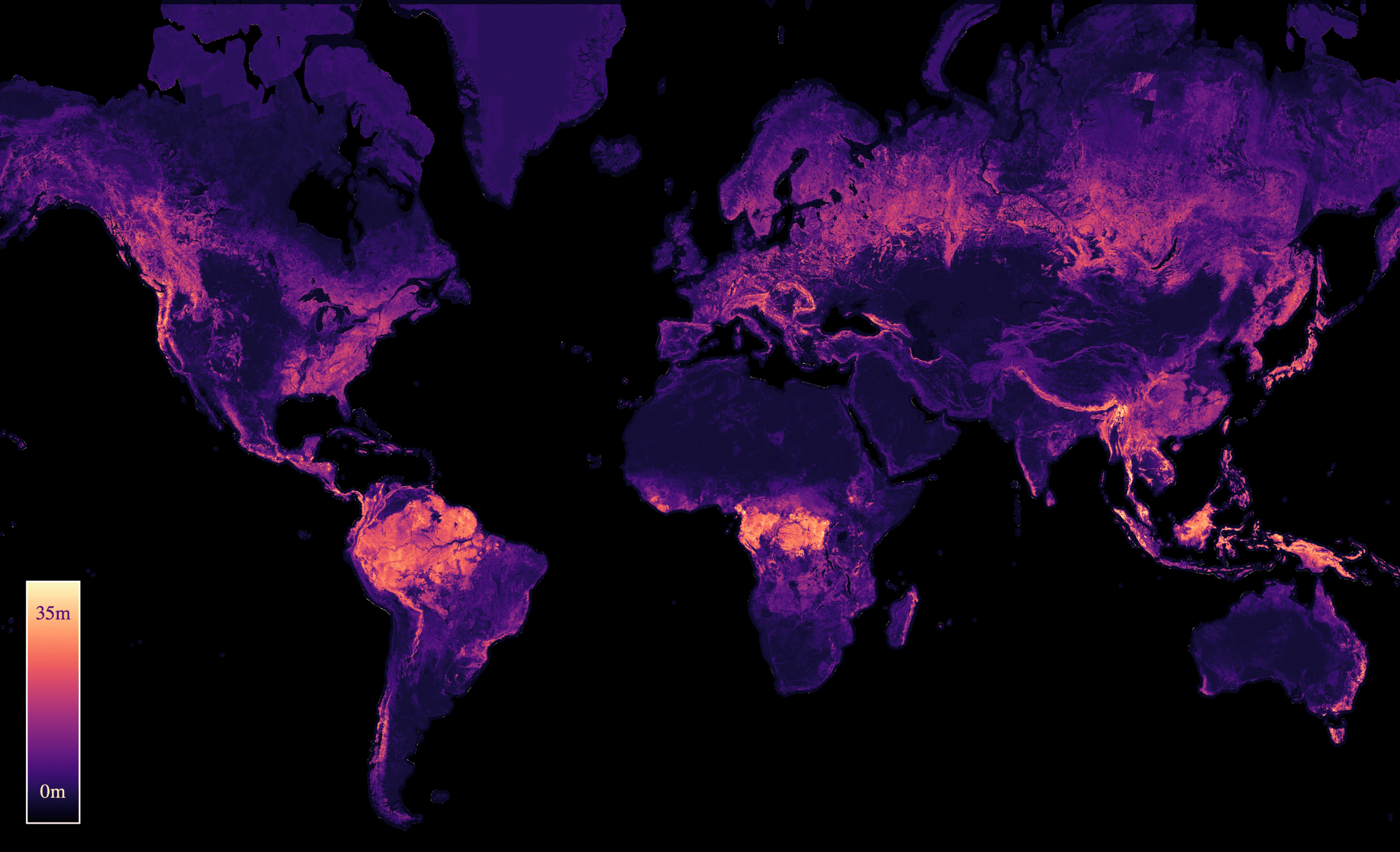 J. Pauls, M. Zimmer, U. M. Kelly, M. Schwartz, S. Saatchi, P. Ciais, S. Pokutta, M. Brandt, and F. GiesekeICML24 41st International Conference on Machine Learning (ICML) 2024
J. Pauls, M. Zimmer, U. M. Kelly, M. Schwartz, S. Saatchi, P. Ciais, S. Pokutta, M. Brandt, and F. GiesekeICML24 41st International Conference on Machine Learning (ICML) 2024We propose a framework for global-scale canopy height estimation based on satellite data. Our model leverages advanced data preprocessing techniques, resorts to a novel loss function designed to counter geolocation inaccuracies inherent in the ground-truth height measurements, and employs data from the Shuttle Radar Topography Mission to effectively filter out erroneous labels in mountainous regions, enhancing the reliability of our predictions in those areas. A comparison between predictions and ground-truth labels yields an MAE / RMSE of 2.43 / 4.73 (meters) overall and 4.45 / 6.72 (meters) for trees taller than five meters, which depicts a substantial improvement compared to existing global-scale maps. The resulting height map as well as the underlying framework will facilitate and enhance ecological analyses at a global scale, including, but not limited to, large-scale forest and biomass monitoring.
@inproceedings{pauls2024estimating, title = {Estimating Canopy Height at Scale}, author = {Pauls, Jan and Zimmer, Max and Kelly, Una M. and Schwartz, Martin and Saatchi, Sassan and Ciais, Philippe and Pokutta, Sebastian and Brandt, Martin and Gieseke, Fabian}, booktitle = {41st International Conference on Machine Learning (ICML)}, year = {2024}, custom = {Earth Engine|https://worldwidemap.projects.earthengine.app/view/canopy-height-2020}, tags = {ml,de,application}, projects = {ai4forest} } -
 C. Lülf, D. M. Lima Martins, S. M. A. Vaz, Y. Zhou, and F. GiesekeSIGIR24 Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (Demo Track) 2024
C. Lülf, D. M. Lima Martins, S. M. A. Vaz, Y. Zhou, and F. GiesekeSIGIR24 Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (Demo Track) 2024The advent of text-image models, most notably CLIP, has signifi- cantly transformed the landscape of information retrieval. These models enable the fusion of various modalities, such as text and images. One significant outcome of CLIP is its capability to allow users to search for images using text as a query, as well as vice versa. This is achieved via a joint embedding of images and text data that can, for instance, be used to search for similar items. De- spite efficient query processing techniques such as approximate nearest neighbor search, the results may lack precision and com- pleteness. We introduce CLIP-Branches, a novel text-image search engine built upon the CLIP architecture. Our approach enhances traditional text-image search engines by incorporating an interac- tive fine-tuning phase, which allows the user to further concretize the search query by iteratively defining positive and negative exam- ples. Our framework involves training a classification model given the additional user feedback and essentially outputs all positively classified instances of the entire data catalog. By building upon re- cent techniques, this inference phase, however, is not implemented by scanning the entire data catalog, but by employing efficient index structures pre-built for the data. Our results show that the fine-tuned results can improve the initial search outputs in terms of relevance and accuracy while maintaining swift response times
@inproceedings{LuelfLMVZG2024CLIPBranches, author = {Lülf, Christian and {Lima Martins}, Denis Mayr and Vaz, Salles Marcos Antonio and Zhou, Yongluan and Gieseke, Fabian}, title = {CLIP-Branches: Interactive Fine-Tuning for Text-Image Retrieval}, booktitle = {Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (Demo Track)}, year = {2024}, address = {Washington, D.C.}, tags = {ml,de}, } -
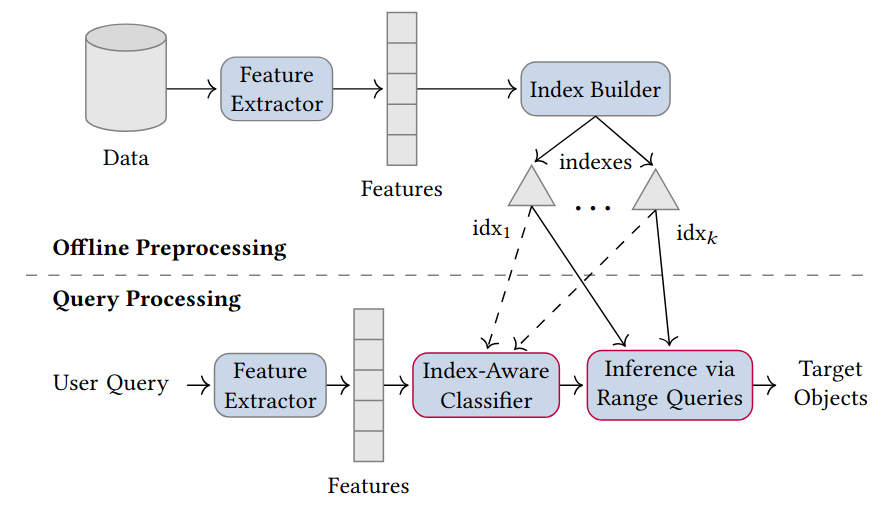 C. Lülf, D. M. Lima Martins, S. M. A. Vaz, Y. Zhou, and F. GiesekeVLDB23 Proceedings of the VLDB Endowment 2023
C. Lülf, D. M. Lima Martins, S. M. A. Vaz, Y. Zhou, and F. GiesekeVLDB23 Proceedings of the VLDB Endowment 2023The vast amounts of data collected in various domains pose great challenges to modern data exploration and analysis. To find “inter- esting” objects in large databases, users typically define a query using positive and negative example objects and train a classifi- cation model to identify the objects of interest in the entire data catalog. However, this approach requires a scan of all the data to apply the classification model to each instance in the data catalog, making this method prohibitively expensive to be employed in large-scale databases serving many users and queries interactively. In this work, we propose a novel framework for such search-by- classification scenarios that allows users to interactively search for target objects by specifying queries through a small set of positive and negative examples. Unlike previous approaches, our frame- work can rapidly answer such queries at low cost without scanning the entire database. Our framework is based on an index-aware construction scheme for decision trees and random forests that transforms the inference phase of these classification models into a set of range queries, which in turn can be efficiently executed by leveraging multidimensional indexing structures. Our experiments show that queries over large data catalogs with hundreds of millions of objects can be processed in a few seconds using a single server, compared to hours needed by classical scanning-based approaches.
@inproceedings{LuelfLMVZG2023FastSearchByClassification, author = {Lülf, Christian and {Lima Martins}, Denis Mayr and Vaz, Salles Marcos Antonio and Zhou, Yongluan and Gieseke, Fabian}, title = {Fast Search-By-Classification for Large-Scale Databases Using Index-Aware Decision Trees and Random Forests}, booktitle = {Proceedings of the VLDB Endowment}, pages = {2845--2857}, volume = {16}, editor = {VLDB, Endowment}, year = {2023}, publisher = {ACM Press}, address = {Vancouver}, issn = {2150-8097}, doi = {10.14778/3611479.3611492}, tags = {ml,de} } -
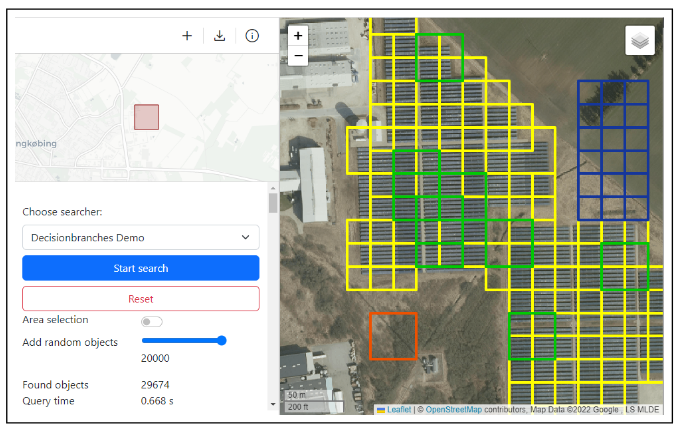 RapidEarth: A Search Engine for Large-Scale Geospatial Imagery Best Demo AwardC. Lülf, D. M. Lima Martins, S. M. A. Vaz, Y. Zhou, and F. GiesekeSIGSPATIAL23 Proceedings of the 31st International Conference on Advances in Geographic Information Systems, SIGSPATIAL, Demo Paper, 2023 (Best Demo Award) 2023
RapidEarth: A Search Engine for Large-Scale Geospatial Imagery Best Demo AwardC. Lülf, D. M. Lima Martins, S. M. A. Vaz, Y. Zhou, and F. GiesekeSIGSPATIAL23 Proceedings of the 31st International Conference on Advances in Geographic Information Systems, SIGSPATIAL, Demo Paper, 2023 (Best Demo Award) 2023Data exploration and analysis in various domains often necessitate the search for specific objects in massive databases. A common search strategy, often known as search-by-classification, resorts to training machine learning models on small sets of positive and negative samples and to performing inference on the entire database to discover additional objects of interest. While such an approach often yields very good results in terms of classification performance, the entire database usually needs to be scanned, a process that can easily take several hours even for medium-sized data catalogs. In this work, we present RapidEarth, a geospatial search-by-classification engine that allows analysts to rapidly search for interesting objects in very large data collections of satellite imagery in a matter of seconds, without the need to scan the entire data catalog. RapidEarth embodies a co-design of multidimensional indexing structures and decision branches, a recently proposed variant of classical decision trees. These decision branches allow RapidEarth to transform the inference phase into a set of range queries, which can be efficiently processed by leveraging the aforementioned multidimensional indexing structures. The main contribution of this work is a geospatial search engine that implements these technical findings.
-
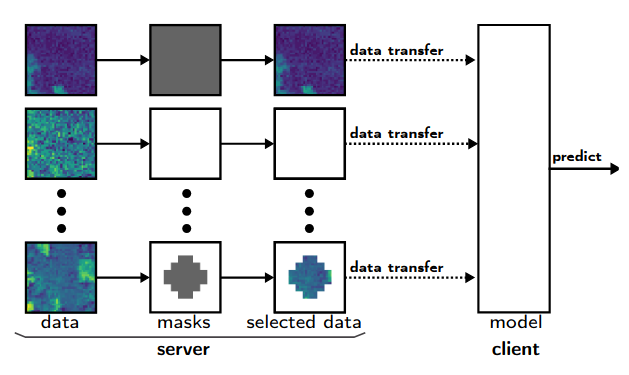 S. Oehmcke, and F. GiesekeSDM22 Proceedings of the 2022 SIAM International Conference on Data Mining (SDM) 2022
S. Oehmcke, and F. GiesekeSDM22 Proceedings of the 2022 SIAM International Conference on Data Mining (SDM) 2022Data are often accommodated on centralized storage servers. This is the case, for instance, in remote sensing and astronomy, where projects produce several petabytes of data every year. While machine learning models are often trained on relatively small subsets of the data, the inference phase typically requires transferring significant amounts of data between the servers and the clients. In many cases, the bandwidth available per user is limited, which then renders the data transfer to be one of the major bottlenecks. In this work, we propose a framework that automatically selects the relevant parts of the input data for a given neural network. The model as well as the associated selection masks are trained simultaneously such that a good model performance is achieved while only a minimal amount of data is selected. During the inference phase, only those parts of the data have to be transferred between the server and the client. We propose both instance-independent and instance-dependent selection masks. The former ones are the same for all instances to be transferred, whereas the latter ones allow for variable transfer sizes per instance. Our experiments show that it is often possible to significantly reduce the amount of data needed to be transferred without affecting the model quality much.
@inproceedings{OehmckeG2022InputSelection, author = {Oehmcke, Stefan and Gieseke, Fabian}, title = {Input Selection for Bandwidth-Limited Neural Network Inference}, booktitle = {Proceedings of the 2022 SIAM International Conference on Data Mining (SDM)}, pages = {280--288}, editor = {Banerjee, Arindam and Zhou, Zhi-Hua and Papalexakis, Evangelos E. and Riondato, Matteo}, year = {2022}, publisher = {SIAM Publications}, address = {USA}, doi = {10.1137/1.9781611977172.32}, tags = {ml,de}, } -
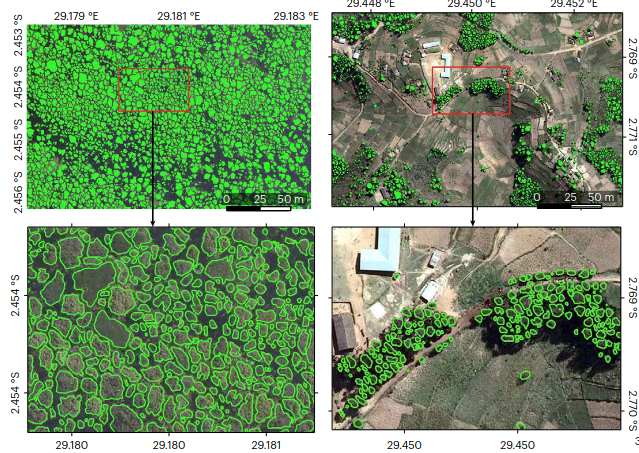 M. Mugabowindekwe, M. Brandt, J. Chave, F. Reiner, D. Skole, A. Kariryaa, C. Igel, P. Hiernaux, P. Ciais, O. Mertz, X. Tong, S. Li, G. Rwanyiziri, T. Dushimiyimana, A. Ndoli, U. Valens, J. Lillesø, F. Gieseke, C. Tucker, S. S. Saatchi, and R. FensholtJOURNALNature Climate Change 2022
M. Mugabowindekwe, M. Brandt, J. Chave, F. Reiner, D. Skole, A. Kariryaa, C. Igel, P. Hiernaux, P. Ciais, O. Mertz, X. Tong, S. Li, G. Rwanyiziri, T. Dushimiyimana, A. Ndoli, U. Valens, J. Lillesø, F. Gieseke, C. Tucker, S. S. Saatchi, and R. FensholtJOURNALNature Climate Change 2022Trees sustain livelihoods and mitigate climate change but a predominance of trees outside forests and limited resources make it difficult for many tropical countries to conduct automated nation-wide inventories. Here, we propose an approach to map the carbon stock of each individual overstory tree at the national scale of Rwanda using aerial imagery from 2008 and deep learning. We show that 72% of the mapped trees are located in farmlands and savannas and 17% in plantations, accounting for 48.6% of the national aboveground carbon stocks. Natural forests cover 11% of the total tree count and 51.4% of the national carbon stocks, with an overall carbon stock uncertainty of 16.9%. The mapping of all trees allows partitioning to any landscapes classification and is urgently needed for effective planning and monitoring of restoration activities as well as for optimization of carbon sequestration, biodiversity and economic benefits of trees.
@article{MugabowindekweBCRSKIHCMTLRDNVLGTSF2022NationWide, author = {Mugabowindekwe, Maurice and Brandt, Martin and Chave, Jerome and Reiner, Florian and Skole, David and Kariryaa, Ankit and Igel, Christian and Hiernaux, Pierre and Ciais, Philippe and Mertz, Ole and Tong, Xiaoye and Li, Sizhuo and Rwanyiziri, Gaspard and Dushimiyimana, Thaulin and Ndoli, Alain and Valens, Uwizeyimana and Lillesø, Jens-Peter and Gieseke, Fabian and Tucker, Compton and Saatchi, Sassan S and Fensholt, Rasmus}, title = {Nation-wide mapping of tree-level aboveground carbon stocks in Rwanda}, journal = {Nature Climate Change}, year = {2022}, volume = {13}, doi = {10.1038/s41558-022-01544-w}, tags = {application,rs}, } -
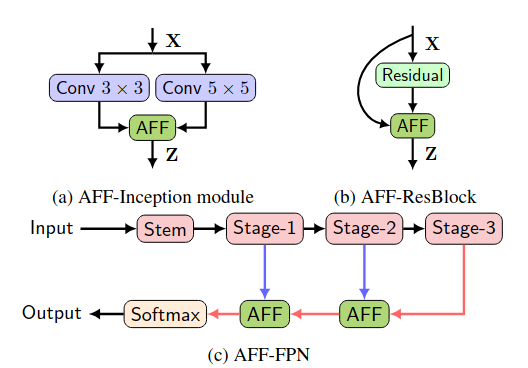 Y. Dai, F. Gieseke, S. Oehmcke, Y. Wu, and K. BarnardWACV21 Proceedings of the Workshop on Applications of Computer Vision (WACV) 2021
Y. Dai, F. Gieseke, S. Oehmcke, Y. Wu, and K. BarnardWACV21 Proceedings of the Workshop on Applications of Computer Vision (WACV) 2021Feature fusion, the combination of features from different layers or branches, is an omnipresent part of modern network architectures. It is often implemented via simple operations, such as summation or concatenation, but this might not be the best choice. In this work, we propose a uniform and general scheme, namely attentional feature fusion, which is applicable for most common scenarios, including feature fusion induced by short and long skip connections as well as within Inception layers. To better fuse features of inconsistent semantics and scales, we propose a multi-scale channel attention module, which addresses issues that arise when fusing features given at different scales. We also demonstrate that the initial integration of feature maps can become a bottleneck and that this issue can be alleviated by adding another level of attention, which we refer to as iterative attentional feature fusion. With fewer layers or parameters, our models outperform state-of-the-art networks on both CIFAR-100 and ImageNet datasets, which suggests that more sophisticated attention mechanisms for feature fusion hold great potential to consistently yield better results compared to their direct counterparts. Our codes and trained models are available online.
@inproceedings{DaiGOWB2021Attentional, author = {Dai, Yimian and Gieseke, Fabian and Oehmcke, Stefan and Wu, Yiquan and Barnard, Kobus}, title = {Attentional Feature Fusion}, booktitle = {Proceedings of the Workshop on Applications of Computer Vision (WACV)}, pages = {3559--3568}, year = {2021}, publisher = {IEEE}, doi = {10.1109/WACV48630.2021.00360}, tags = {ml}, } -
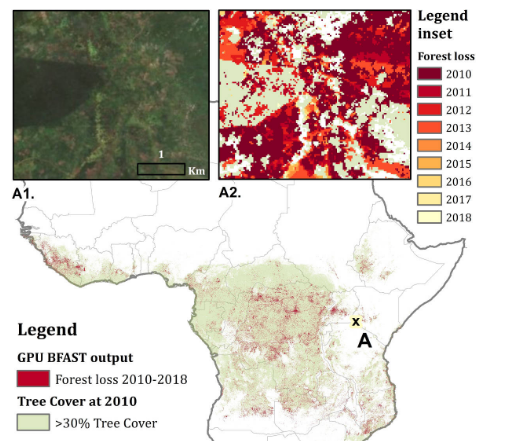 F. Gieseke, S. Rosca, T. Henriksen, J. Verbesselt, and C. E. OanceaICDE20 Proceedings of the 36th IEEE International Conference on Data Engineering (ICDE) 2020
F. Gieseke, S. Rosca, T. Henriksen, J. Verbesselt, and C. E. OanceaICDE20 Proceedings of the 36th IEEE International Conference on Data Engineering (ICDE) 2020Large amounts of satellite data are now becoming available, which, in combination with appropriate change detection methods, offer the opportunity to derive accurate information on timing and location of disturbances such as deforestation events across the earth surface. Typical scenarios require the analysis of billions of image patches/pixels. While various change detection techniques have been proposed in the literature, the associated implementations usually do not scale well, which renders the corresponding analyses computationally very expensive or even impossible. In this work, we propose a novel massively-parallel implementation for a state-of-the-art change detection method and demonstrate its potential in the context of monitoring deforestation. The novel implementation can handle large scenarios in a few hours or days using cheap commodity hardware, compared to weeks or even years using the existing publicly available code, and enables researchers, for the first time, to conduct global-scale analyses covering large parts of our Earth using little computational resources. From a technical perspective, we provide a high-level parallel algorithm specification along with several performance-critical optimizations dedicated to efficiently map the specified parallelism to modern parallel devices. While a particular change detection method is addressed in this work, the algorithmic building blocks provided are also of immediate relevance to a wide variety of related approaches in remote sensing and other fields.
@inproceedings{GiesekeRHVO2020MassivelyParallel, author = {Gieseke, Fabian and Rosca, Sabina and Henriksen, Troels and Verbesselt, Jan and Oancea, Cosmin Eugen}, title = {Massively-Parallel Change Detection for Satellite Time Series Data with Missing Values}, booktitle = {Proceedings of the 36th {IEEE} International Conference on Data Engineering (ICDE)}, pages = {385--396}, year = {2020}, address = {Dallas, USA}, doi = {10.1109/ICDE48307.2020.00040}, tags = {de,rs}, } -
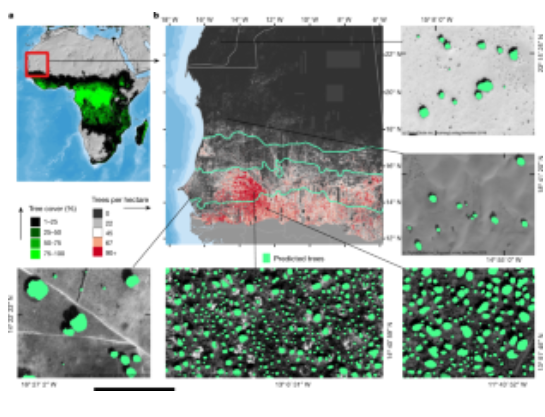 M. Brandt, C. Tucker, A. Kariryaa, K. Rasmussen, C. Abel, J. Small, J. Chave, L. Rasmussen, P. Hiernaux, A. Diouf, L. Kergoat, O. Mertz, C. Igel, F. Gieseke, J. Schöning, S. Li, K. Melocik, J. Meyer, SinnoS, E. Romero, E. Glennie, A. Montagu, M. Dendoncker, and R. FensholtJOURNALNature 2020
M. Brandt, C. Tucker, A. Kariryaa, K. Rasmussen, C. Abel, J. Small, J. Chave, L. Rasmussen, P. Hiernaux, A. Diouf, L. Kergoat, O. Mertz, C. Igel, F. Gieseke, J. Schöning, S. Li, K. Melocik, J. Meyer, SinnoS, E. Romero, E. Glennie, A. Montagu, M. Dendoncker, and R. FensholtJOURNALNature 2020A large proportion of dryland trees and shrubs (hereafter referred to collectively as trees) grow in isolation, without canopy closure. These non-forest trees have a crucial role in biodiversity, and provide ecosystem services such as carbon storage, food resources and shelter for humans and animals. However, most public interest relating to trees is devoted to forests, and trees outside of forests are not well-documented. Here we map the crown size of each tree more than 3 m2 in size over a land area that spans 1.3 million km2 in the West African Sahara, Sahel and sub-humid zone, using submetre-resolution satellite imagery and deep learning. We detected over 1.8 billion individual trees (13.4 trees per hectare), with a median crown size of 12 m2, along a rainfall gradient from 0 to 1,000 mm per year. The canopy cover increases from 0.1% (0.7 trees per hectare) in hyper-arid areas, through 1.6% (9.9 trees per hectare) in arid and 5.6% (30.1 trees per hectare) in semi-arid zones, to 13.3% (47 trees per hectare) in sub-humid areas. Although the overall canopy cover is low, the relatively high density of isolated trees challenges prevailing narratives about dryland desertification, and even the desert shows a surprisingly high tree density. Our assessment suggests a way to monitor trees outside of forests globally, and to explore their role in mitigating degradation, climate change and poverty.
@article{BrandtTKRASCRHDKMIGSLMMSRGMDF2020AnUnexpectedly, author = {Brandt, M and Tucker, C and Kariryaa, A and Rasmussen, K and Abel, C and Small, J and Chave, J and Rasmussen, L and Hiernaux, P and Diouf, A and Kergoat, L and Mertz, O and Igel, C and Gieseke, F and Schöning, J and Li, S and Melocik, K and Meyer, J and SinnoS and Romero, E and Glennie, E and Montagu, A and Dendoncker, M and Fensholt, R}, title = {An unexpectedly large count of trees in the West African Sahara and Sahel}, journal = {Nature}, year = {2020}, volume = {2020}, doi = {10.1038/s41586-020-2824-5}, tags = {application,rs,ml} } -
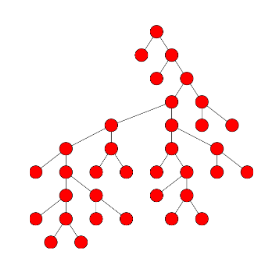 F. Gieseke, and C. IgelKDD18 Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD 2018, London, UK, August 19-23, 2018 2018
F. Gieseke, and C. IgelKDD18 Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD 2018, London, UK, August 19-23, 2018 2018Without access to large compute clusters, building random forests on large datasets is still a challenging problem. This is, in particular, the case if fully-grown trees are desired. We propose a simple yet effective framework that allows to efficiently construct ensembles of huge trees for hundreds of millions or even billions of training instances using a cheap desktop computer with commodity hardware. The basic idea is to consider a multi-level construction scheme, which builds top trees for small random subsets of the available data and which subsequently distributes all training instances to the top trees’ leaves for further processing. While being conceptually simple, the overall efficiency crucially depends on the particular implementation of the different phases. The practical merits of our approach are demonstrated using dense datasets with hundreds of millions of training instances.
@inproceedings{GiesekeI2018TrainingBig, author = {Gieseke, Fabian and Igel, Christian}, title = {Training Big Random Forests with Little Resources}, booktitle = {Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD 2018, London, UK, August 19-23, 2018}, pages = {1445--1454}, year = {2018}, publisher = {ACM}, doi = {10.1145/3219819.3220124}, tags = {ml,de}, } -
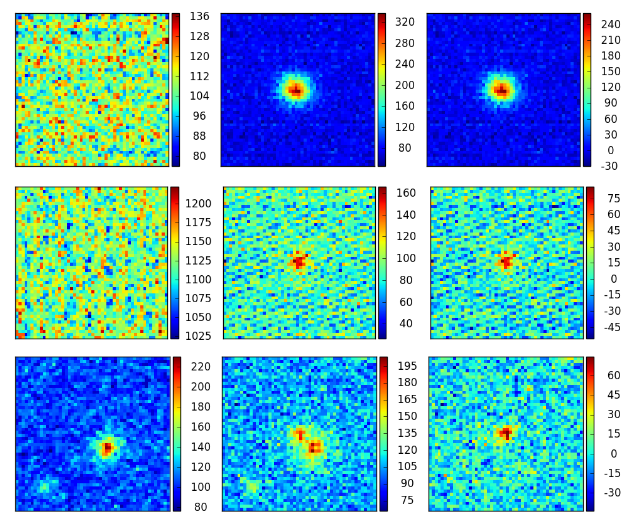 F. Gieseke, S. Bloemen, C. Bogaard, T. Heskes, J. Kindler, R. A. Scalzo, V. A. Ribeiro, J. Roestel, P. J. Groot, F. Yuan, A. Möller, and B. E. TuckerJOURNALMonthly Notices of the Royal Astronomical Society (MNRAS) 2017
F. Gieseke, S. Bloemen, C. Bogaard, T. Heskes, J. Kindler, R. A. Scalzo, V. A. Ribeiro, J. Roestel, P. J. Groot, F. Yuan, A. Möller, and B. E. TuckerJOURNALMonthly Notices of the Royal Astronomical Society (MNRAS) 2017Current synoptic sky surveys monitor large areas of the sky to find variable and transient astronomical sources. As the number of detections per night at a single telescope easily exceeds several thousand, current detection pipelines make intensive use of machine learning algorithms to classify the detected objects and to filter out the most interesting candidates. A number of upcoming surveys will produce up to three orders of magnitude more data, which renders high-precision classification systems essential to reduce the manual and, hence, expensive vetting by human experts. We present an approach based on convolutional neural networks to discriminate between true astrophysical sources and artefacts in reference-subtracted optical images. We show that relatively simple networks are already competitive with state-of-the-art systems and that their quality can further be improved via slightly deeper networks and additional pre-processing steps – eventually yielding models outperforming state-of-the-art systems. In particular, our best model correctly classifies about 97.3 per cent of all ‘real’ and 99.7 per cent of all ‘bogus’ instances on a test set containing 1942 ‘bogus’ and 227 ‘real’ instances in total. Furthermore, the networks considered in this work can also successfully classify these objects at hand without relying on difference images, which might pave the way for future detection pipelines not containing image subtraction steps at all.
@article{GiesekeEtAl2017, author = {Gieseke, Fabian and Bloemen, Steven and van den Bogaard, Cas and Heskes, Tom and Kindler, Jonas and Scalzo, Richard A. and Ribeiro, Valerio A.R.M. and van Roestel, Jan and Groot, Paul J. and Yuan, Fang and Möller, Anais and Tucker, Brad E.}, title = {Convolutional Neural Networks for Transient Candidate Vetting in Large-Scale Surveys}, journal = {Monthly Notices of the Royal Astronomical Society {(MNRAS)}}, year = {2017}, pages = {3101-3114}, volume = {472}, number = {3}, publisher = {Oxford University Press}, tags = {application,ml}, } -
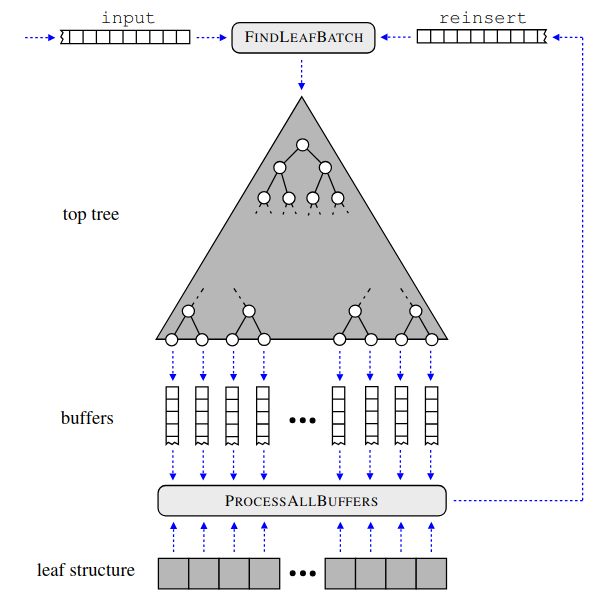 F. Gieseke, J. Heinermann, C. E. Oancea, and C. IgelICML14 Proceedings of the 31th International Conference on Machine Learning, ICML 2014, Beijing, China, 21-26 June 2014 2014
F. Gieseke, J. Heinermann, C. E. Oancea, and C. IgelICML14 Proceedings of the 31th International Conference on Machine Learning, ICML 2014, Beijing, China, 21-26 June 2014 2014We present a new approach for combining k-d trees and graphics processing units for near- est neighbor search. It is well known that a di- rect combination of these tools leads to a non- satisfying performance due to conditional com- putations and suboptimal memory accesses. To alleviate these problems, we propose a variant of the classical k-d tree data structure, called buffer k-d tree, which can be used to reorganize the search. Our experiments show that we can take advantage of both the hierarchical subdivi- sion induced by k-d trees and the huge computa- tional resources provided by today’s many-core devices. We demonstrate the potential of our ap- proach in astronomy, where hundreds of million nearest neighbor queries have to be processed.
@inproceedings{GiesekeHOI14, author = {Gieseke, Fabian and Heinermann, Justin and Oancea, Cosmin E. and Igel, Christian}, title = {Buffer k-d Trees: Processing Massive Nearest Neighbor Queries on GPUs}, booktitle = {Proceedings of the 31th International Conference on Machine Learning, {ICML} 2014, Beijing, China, 21-26 June 2014}, series = {{JMLR} Workshop and Conference Proceedings}, volume = {32}, pages = {172--180}, publisher = {JMLR.org}, year = {2014}, tags = {ml}, } -
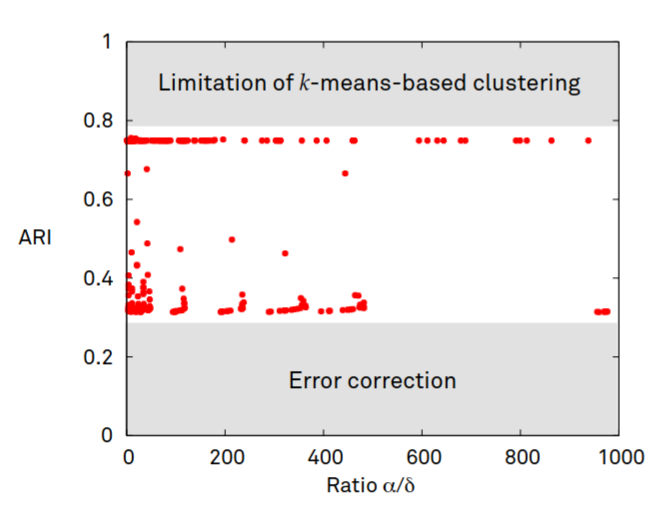
 F. Gieseke, T. Pahikkala, and C. IgelACML13 Asian Conference on Machine Learning, ACML 2013, Canberra, ACT, Australia, November 13-15, 2013 2013
F. Gieseke, T. Pahikkala, and C. IgelACML13 Asian Conference on Machine Learning, ACML 2013, Canberra, ACT, Australia, November 13-15, 2013 2013Maximum margin clustering can be regarded as the direct extension of support vector machines to unsupervised learning scenarios. The goal is to partition unlabeled data into two classes such that a subsequent application of a support vector machine would yield the overall best result (with respect to the optimization problem associated with support vector machines). While being very appealing from a conceptual point of view, the combinatorial nature of the induced optimization problem ren- ders a direct application of this concept difficult. In order to obtain efficient optimization schemes, various surrogates of the original problem definition have been proposed in the literature. In this work, we consider one of these variants, called unsupervised regularized least-squares classifica- tion, which is based on the square loss, and develop polynomial upper runtime bounds for the induced combinatorial optimization task. In particular, we show that for n patterns and kernel ma- trix of fixed rank r (with given eigendecomposition), one can obtain an optimal solution in O(nr) time for r ≤ 2 and in O(nr−1) time for r ≥ 3. The algorithmic framework is based on an inter- esting connection to the field of quadratic zero-one programming and permits the computation of exact solutions for the more general case of non-linear kernel functions in polynomial time.
@inproceedings{GiesekePI13, author = {Gieseke, Fabian and Pahikkala, Tapio and Igel, Christian}, editor = {Ong, Cheng Soon and Ho, Tu Bao}, title = {Polynomial Runtime Bounds for Fixed-Rank Unsupervised Least-Squares Classification}, booktitle = {Asian Conference on Machine Learning, {ACML} 2013, Canberra, ACT, Australia, November 13-15, 2013}, series = {{JMLR} Workshop and Conference Proceedings}, volume = {29}, pages = {62--71}, publisher = {JMLR.org}, year = {2013}, tags = {ml}, } -
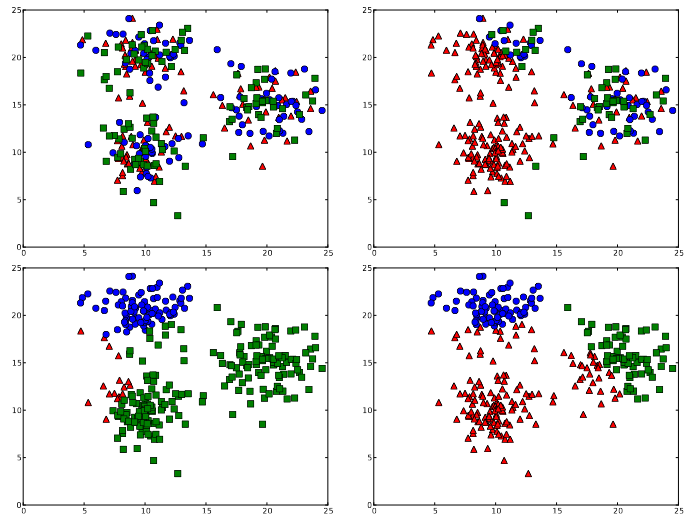 T. Pahikkala, A. Airola, F. Gieseke, and O. KramerICDM12 12th IEEE International Conference on Data Mining, ICDM 2012, Brussels, Belgium, December 10-13, 2012 2012
T. Pahikkala, A. Airola, F. Gieseke, and O. KramerICDM12 12th IEEE International Conference on Data Mining, ICDM 2012, Brussels, Belgium, December 10-13, 2012 2012Regularized least-squares classification is one of the most promising alternatives to standard support vector machines, with the desirable property of closed-form solutions that can be obtained analytically, and efficiently. While the supervised, and mostly binary case has received tremendous attention in recent years, unsupervised multi-class settings have not yet been considered. In this work we present an efficient implementation for the unsupervised extension of the multi-class regularized least-squares classification framework, which is, to the best of the authors’ knowledge, the first one in the literature addressing this task. The resulting kernel-based framework efficiently combines steepest descent strategies with powerful meta-heuristics for avoiding local minima. The computational efficiency of the overall approach is ensured through the application of matrix algebra shortcuts that render efficient updates of the intermediate can- didate solutions possible. Our experimental evaluation indicates the potential of the novel method, and demonstrates its superior clustering performance over a variety of competing methods on real-world data sets.
@inproceedings{PahikkalaAGK12, author = {Pahikkala, Tapio and Airola, Antti and Gieseke, Fabian and Kramer, Oliver}, editor = {Zaki, Mohammed Javeed and Siebes, Arno and Yu, Jeffrey Xu and Goethals, Bart and Webb, Geoffrey I. and Wu, Xindong}, title = {Unsupervised Multi-class Regularized Least-Squares Classification}, booktitle = {12th {IEEE} International Conference on Data Mining, {ICDM} 2012, Brussels, Belgium, December 10-13, 2012}, pages = {585--594}, publisher = {{IEEE} Computer Society}, year = {2012}, doi = {10.1109/ICDM.2012.71}, tags = {ml}, } -
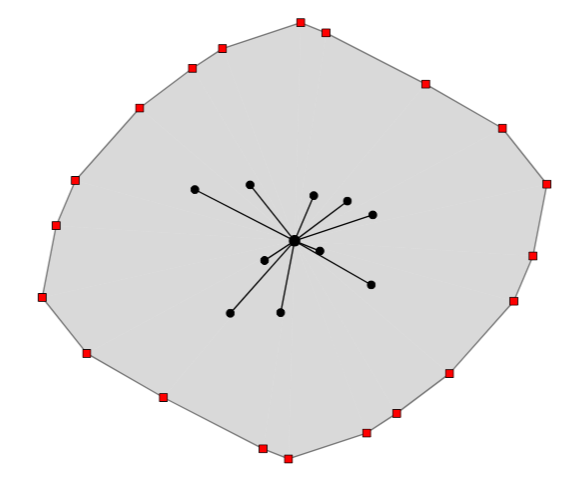
 F. Gieseke, G. Moruz, and J. VahrenholdICDM10 ICDM 2010, The 10th IEEE International Conference on Data Mining, Sydney, Australia, 14-17 December 2010 2010
F. Gieseke, G. Moruz, and J. VahrenholdICDM10 ICDM 2010, The 10th IEEE International Conference on Data Mining, Sydney, Australia, 14-17 December 2010 2010We develop a k-d tree variant that is resilient to a pre-described number of memory corruptions while still using only linear space. We show how to use this data structure in the context of clustering in high-radiation environments and demonstrate that our approach leads to a significantly higher resiliency rate compared to previous results.
@inproceedings{GiesekeMV10, author = {Gieseke, Fabian and Moruz, Gabriel and Vahrenhold, Jan}, editor = {Webb, Geoffrey I. and Liu, Bing and Zhang, Chengqi and Gunopulos, Dimitrios and Wu, Xindong}, title = {Resilient K-d Trees: K-Means in Space Revisited}, booktitle = {{ICDM} 2010, The 10th {IEEE} International Conference on Data Mining, Sydney, Australia, 14-17 December 2010}, pages = {815--820}, publisher = {{IEEE} Computer Society}, year = {2010}, doi = {10.1109/ICDM.2010.94}, tags = {de}, } -
 F. Gieseke, T. Pahikkala, and O. KramerICML09 Proceedings of the 26th Annual International Conference on Machine Learning, ICML 2009, Montreal, Quebec, Canada, June 14-18, 2009 2009
F. Gieseke, T. Pahikkala, and O. KramerICML09 Proceedings of the 26th Annual International Conference on Machine Learning, ICML 2009, Montreal, Quebec, Canada, June 14-18, 2009 2009The maximum margin clustering approach is a recently proposed extension of the concept of support vector machines to the clustering problem. Briefly stated, it aims at finding an optimal partition of the data into two classes such that the margin induced by a subsequent application of a support vector machine is maximal. We propose a method based on stochastic search to address this hard optimization problem. While a direct implementation would be infeasible for large data sets, we present an efficient computa- tional shortcut for assessing the “quality” of intermediate solutions. Experimental results show that our approach outperforms existing methods in terms of clustering accuracy.
@inproceedings{GiesekePK09, author = {Gieseke, Fabian and Pahikkala, Tapio and Kramer, Oliver}, editor = {Danyluk, Andrea Pohoreckyj and Bottou, L{\'{e}}on and Littman, Michael L.}, title = {Fast evolutionary maximum margin clustering}, booktitle = {Proceedings of the 26th Annual International Conference on Machine Learning, {ICML} 2009, Montreal, Quebec, Canada, June 14-18, 2009}, series = {{ACM} International Conference Proceeding Series}, volume = {382}, pages = {361--368}, publisher = {{ACM}}, year = {2009}, doi = {10.1145/1553374.1553421}, tags = {ml}, }




















