Publications tagged "ml"
-
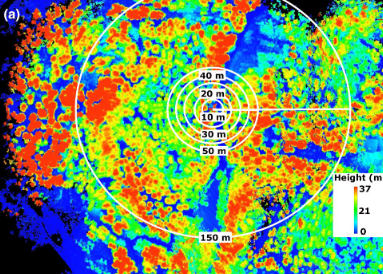 J. C. Revenga, S. Oehmcke, M. Gharun, F. Sutter, F. Gieseke, K. Trepekli, N. Buchmann, and A. DammEcological Solutions and Evidence 2026
J. C. Revenga, S. Oehmcke, M. Gharun, F. Sutter, F. Gieseke, K. Trepekli, N. Buchmann, and A. DammEcological Solutions and Evidence 2026Abstract Forest structure, tree diameter, and above-ground biomass (AGB) are central variables in trait-based ecology and forest management, and recent advances in Unmanned Aerial Vehicle (UAV) and LiDAR surveys have substantially improved tree-level phenotyping of these attributes. Building on these developments, machine learning (ML) applications are increasingly used to refine tree diameter estimates and, by extension, improve AGB predictions derived from allometric relationships. Here, we evaluated the capacity of shallow learning methods to leverage local contextual information surrounding a tree of interest to improve predictions of stem diameter and tree-level AGB over 33 ha of a Norway spruce forest (Davos, CH). Our objectives were to (i) characterize gradients of tree height, (ii) examine group-level morphology of tree assemblages as an indicator of forest structural organization and (iii) assess whether these patterns can be leveraged to improve tree diameter and AGB predictions. We segmented the LiDAR point cloud scene into individual canopies and focused on LiDAR-derived tree canopy features. We then used local indicators of spatial association of tree heights to characterize local context and identify tree assemblages within the forest. Assemblage-level metrics were first analysed to characterize forest spatial structure and ecological similarity, and subsequently evaluated as additional predictors in ML regression experiments for tree diameter. Performance was compared between twin regression methods that either incorporated assemblage metrics (i.e. context-aware) or did not. Improvements provided by context awareness were assessed in terms of accuracy gained in estimating tree diameter and AGB. We evaluated three shallow learning methods using nested cross-validation and considered two datasets from the same site: one spatially sparse, based on scattered sampling plots, and one spatially continuous. In both sparse and continuous datasets, we found enhanced prediction performance in context-aware regressions, with RMSE for tree diameter estimation reduced by 4.1% and 0.8%, respectively, suggesting that heterogeneous local context supports improved estimates. Practical implication: Gradients of tree height can reflect underlying ecological drivers of forest structure, and this structural information may be leveraged to enhance predictions of tree diameter and AGB. The proposed method is fully native to UAV LiDAR data.
-
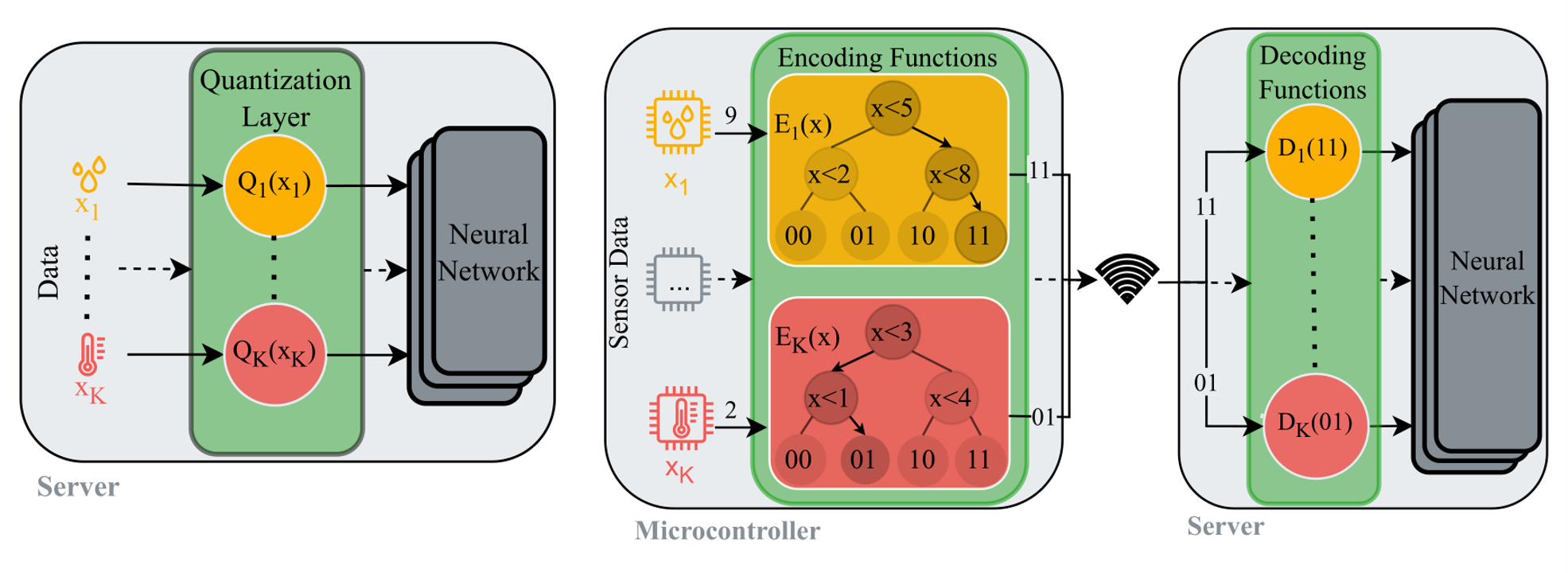 K. Schrödter, J. Stenkamp, N. Herrmann, and F. GiesekeCPAL26 Third Conference on Parsimony and Learning (CPAL) 2026
K. Schrödter, J. Stenkamp, N. Herrmann, and F. GiesekeCPAL26 Third Conference on Parsimony and Learning (CPAL) 2026The growing demand for machine learning applications in the context of the Internet of Things calls for new approaches to optimize the use of limited compute and memory resources. Despite significant progress that has been made w.r.t. reducing model sizes and improving efficiency, many applications still require remote servers to provide the required resources. However, such approaches rely on transmitting data from edge devices to remote servers, which may not always be feasible due to bandwidth, latency, or energy constraints. We propose a task-specific, trainable feature quantization layer that compresses the input features of a neural network. This can significantly reduce the amount of data that needs to be transferred from the device to a remote server. In particular, the layer allows each input feature to be quantized to a user-defined number of bits, enabling a simple on-device compression at the time of data collection. The layer is designed to approximate step functions with sigmoids, enabling trainable quantization thresholds. By concatenating outputs from multiple sigmoids, introduced as bitwise soft quantization, it achieves trainable quantized values when integrated with a neural network. We compare our method to full-precision inference as well as to several quantization baselines. Experiments show that our approach outperforms standard quantization methods, while maintaining accuracy levels close to those of full-precision models. In particular, depending on the dataset at hand, compression factors of to can be achieved without significant performance loss.
@inproceedings{schroedter2026bitwisequant, title = {Trainable Bitwise Soft Quantization for Input Feature Compression}, author = {Schrödter, Karsten and Stenkamp, Jan and Herrmann, Nina and Gieseke, Fabian}, booktitle = {Third Conference on Parsimony and Learning (CPAL)}, year = {2026}, tags = {ml,application,rs}, projects = {ai4forest} } -
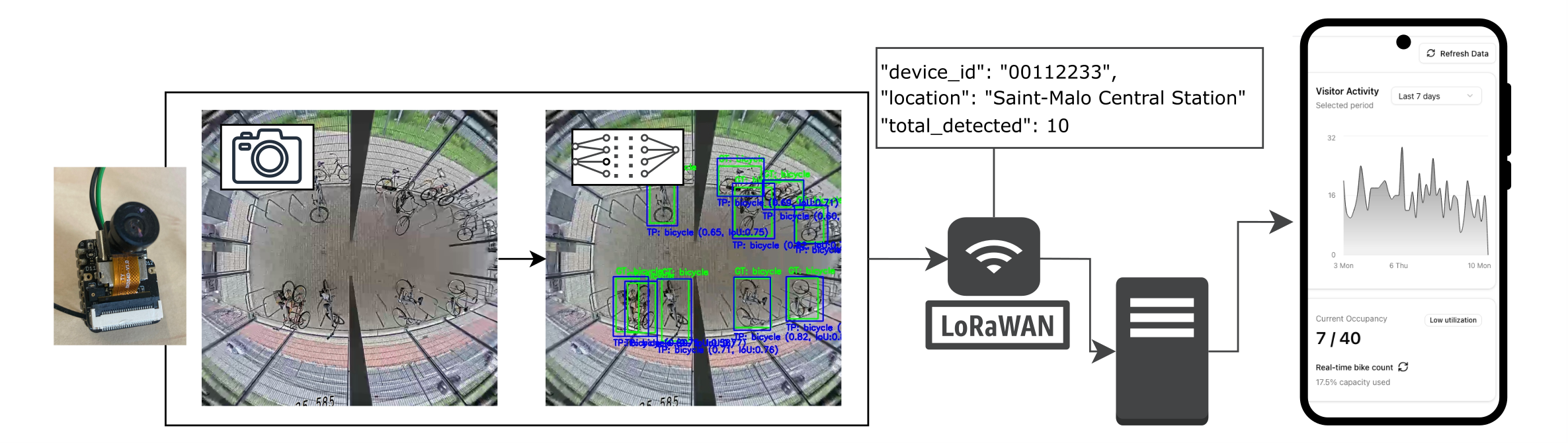 J. Stenkamp, M. Hunke, C. Karatas, S. Kirchhoff, C. Knaden, P. Naebers, L. Zhao, B. Karic, F. Gieseke, and N. HerrmannSENSYS26 ACM/IEEE International Conference on Embedded Artificial Intelligence and Sensing Systems (SenSys) 2026
J. Stenkamp, M. Hunke, C. Karatas, S. Kirchhoff, C. Knaden, P. Naebers, L. Zhao, B. Karic, F. Gieseke, and N. HerrmannSENSYS26 ACM/IEEE International Conference on Embedded Artificial Intelligence and Sensing Systems (SenSys) 2026As cities strive to reduce car dependency and promote sustainable transportation, encouraging bicycle usage becomes a vital part of the urban planning process. The existence of a sufficient number of bicycle storage facilities is a key building block, as it reduces the likelihood of bicycle theft and the necessity for bicycle repairs. By monitoring the utilization of bicycle parking lots, supply shortfalls can be detected, and users can be informed about the availability of slots. However, detection systems face multiple challenges. Equipping every parking slot with individual sensors is costly, and transmitting visual data can raise privacy concerns or even discourage users. To address this problem, embedded machine learning can be used to process visual data locally and transmit only the resulting count to a central server. This work sets out a real-world use case for microcontrollers that are equipped with a camera and an embedded machine learning model for the purpose of counting parked bicycles. A custom dataset was collected and labeled to train an object-detection model, which was subsequently compressed and deployed on an ESP32-S3 microcontroller that processes the image data locally and transmits only the bicycle count to a remote server via LoRaWAN. The model compression incurs only a marginal performance degradation, with the compressed model still achieving an AP@50 of 0.91. Hence, our approach demonstrates the practical realization of recent theoretical advances in tiny machine learning and provides a viable solution for monitoring bicycle parking facilities in real-world settings.
@inproceedings{Stenkampcountingparkedbicycles, title = {Counting Parked Bicycles on the Edge - A TinyML Smart City Application}, author = {Stenkamp, Jan and Hunke, Mathis and Karatas, Cem and Kirchhoff, Steffen and Knaden, Christoph and Naebers, Paul and Zhao, Lige and Karic, Benjamin and Gieseke, Fabian and Herrmann, Nina}, booktitle = {ACM/IEEE International Conference on Embedded Artificial Intelligence and Sensing Systems (SenSys)}, year = {2026}, tags = {ml,application,rs}, projects = {tinyaiot}, doi = {10.1145/3774906.3802788} } -
 N. Herrmann, J. Stenkamp, B. Karic, S. Oehmcke, and F. GiesekeICLR26 The Fourteenth International Conference on Learning Representations (ICLR) 2026
N. Herrmann, J. Stenkamp, B. Karic, S. Oehmcke, and F. GiesekeICLR26 The Fourteenth International Conference on Learning Representations (ICLR) 2026Deploying machine learning models on compute-constrained devices has become a key building block of modern IoT applications. In this work, we present a compression scheme for boosted decision trees, addressing the growing need for lightweight machine learning models. Specifically, we provide techniques for training compact boosted decision tree ensembles that exhibit a reduced memory footprint by rewarding, among other things, the reuse of features and thresholds during training. Our experimental evaluation shows that models achieved the same performance with a compression ratio of 4–16x compared to LightGBM models using an adapted training process and an alternative memory layout. Once deployed, the corresponding IoT devices can operate independently of constant communication or external energy supply, and, thus, autonomously, requiring only minimal computing power and energy. This capability opens the door to a wide range of IoT applications, including remote monitoring, edge analytics, and real-time decision making in isolated or power-limited environments.
@inproceedings{treesonadiet, title = {Boosted Trees on a Diet: Compact Models for Resource-Constrained Devices}, author = {Herrmann, Nina and Stenkamp, Jan and Karic, Benjamin and Oehmcke, Stefan and Gieseke, Fabian}, booktitle = {The Fourteenth International Conference on Learning Representations (ICLR)}, year = {2026}, tags = {ml,de,energy,rs}, projects = {tinyaiot}, url = {https://openreview.net/forum?id=batDcksZsh} } -
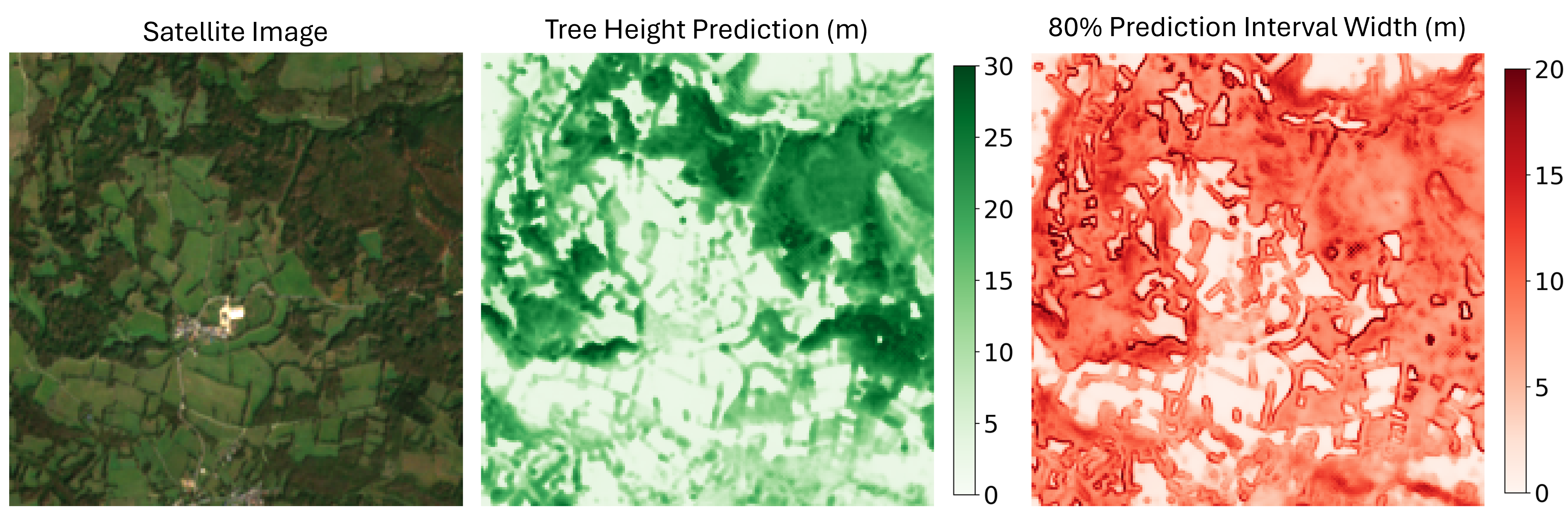 K. Schrödter, J. Pauls, and F. GiesekeAISTATS26 Twenty-Ninth Annual Conference on Artificial Intelligence and Statistics (AISTATS) 2026
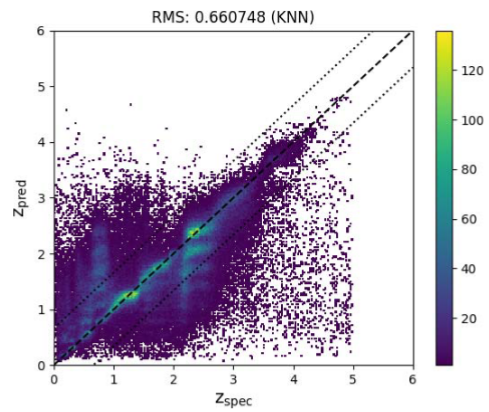
K. Schrödter, J. Pauls, and F. GiesekeAISTATS26 Twenty-Ninth Annual Conference on Artificial Intelligence and Statistics (AISTATS) 2026Accurate tree height estimation is vital for ecological monitoring and biomass assessment. We apply quantile regression to existing tree height estimation models based on satellite data to incorporate uncertainty quantification. Most current approaches on tree height estimation rely on point predictions, which limits their applicability in risk-sensitive scenarios. In this work, we show that with minor modifications to the prediction head, existing models can be adapted to provide statistically calibrated uncertainty estimates via quantile regression. Furthermore, we demonstrate how our results correlate with known challenges in remote sensing (e.g., terrain complexity, vegetation heterogeneity), indicating that the model is less confident in more challenging conditions.
@inproceedings{schroedter2026uncertaintytree, title = {Canopy Tree Height Estimation using Quantile Regression: Modeling and Evaluating Uncertainty in Remote Sensing}, author = {Schrödter, Karsten and Pauls, Jan and Gieseke, Fabian}, booktitle = {Twenty-Ninth Annual Conference on Artificial Intelligence and Statistics (AISTATS)}, year = {2026}, tags = {ml,application,rs}, projects = {ai4forest} } -
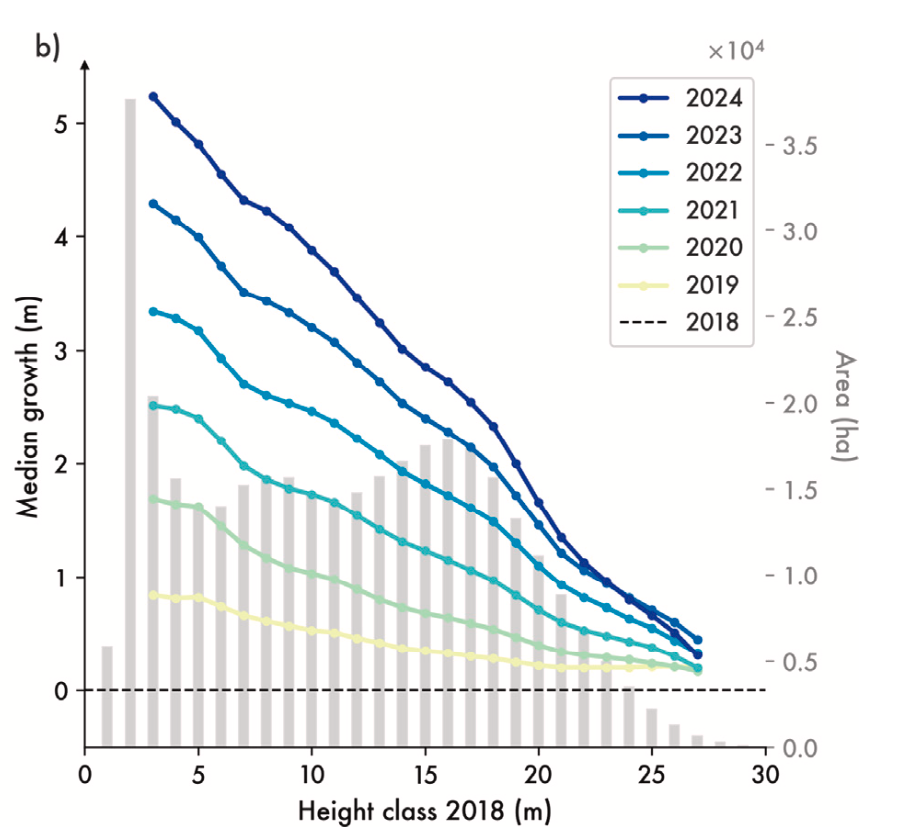 M. Schwartz, P. Ciais, E. Sean, A. de Truchis, C. Vega, N. Besic, I. Fayad, J. Wigneron, S. Brood, A. Pelissier-Tanon, J. Pauls, G. Belouze, and Y. XuRemote Sensing of Environment 2025
M. Schwartz, P. Ciais, E. Sean, A. de Truchis, C. Vega, N. Besic, I. Fayad, J. Wigneron, S. Brood, A. Pelissier-Tanon, J. Pauls, G. Belouze, and Y. XuRemote Sensing of Environment 2025High-resolution mapping of forest attributes is crucial for ecosystem monitoring and carbon budget assessments. Recent advancements have leveraged satellite imagery and deep learning algorithms to generate high-resolution forest height maps. While these maps provide valuable snapshots of forest conditions, they lack the temporal resolution to estimate forest-related carbon fluxes or track annual changes. Few studies have produced annual forest height, volume, or biomass change maps validated at the forest stand level. To address this limitation, we developed a deep learning framework, coupling data from Sentinel-1 (S1), Sentinel-2 (S2) and from the Global Ecosystem Dynamics Investigation (GEDI) mission, to generate a time series of forest height, growing stock volume, and aboveground biomass at 10 to 30-m spatial resolution that we refer to as FORMS-T (FORest Multiple Satellite Time series). Unlike previous studies, we train our model on individual S2 scenes, rather than on growing season composites, to account for acquisition variability and improve generalization across years. We produced these maps for France over seven years (2018–2024) for height at 10 m resolution and further converted them to 30 m maps of growing stock volume and aboveground biomass using leaf type-specific allometric equations. Evaluation against the French National Forest Inventory (NFI) showed an average mean absolute error of 3.07 m for height (r2=0.68) across all years, 86 m3 ha-1 for volume and 65.1 Mg ha-1 for biomass. We further evaluated FORMS-T capacity to capture growth on a site where two successive airborne laser scanning (ALS) campaigns were available, showing a good agreement with ALS data when aggregating at coarser spatial resolution (r2=0.60, MAE=0.27 m for the 2020–2022 growth of trees between 10 and 15 m in 5 km pixels). Additionally, we compared our results to the NFI-based wood volume production at regional level and obtained a good agreement with a MAE of 1.45 m3 ha-1 yr-1 and r2 of 0.59. We then leveraged our height change maps to derive species-specific growth curves and compared them to ground-based measurements, highlighting distinct growth dynamics and regional variations in forest management practices. Further development of such maps could contribute to the assessment of forest-related carbon stocks and fluxes, contributing to the formulation of a comprehensive carbon budget at the country scale, and supporting global efforts to mitigate climate change.
-
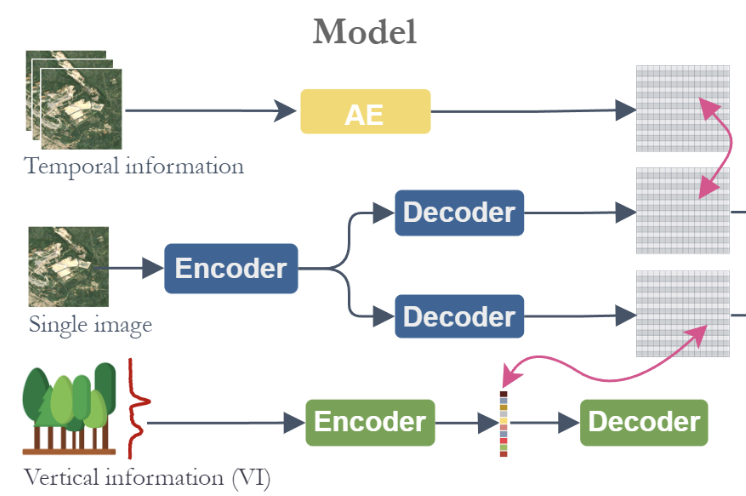 I. Fayad, M. Zimmer, M. Schwartz, P. Ciais, F. Gieseke, G. Belouze, S. Brood, A. De Truchis, and A. d’AspremontICML25 42nd International Conference on Machine Learning (ICML) 2025
I. Fayad, M. Zimmer, M. Schwartz, P. Ciais, F. Gieseke, G. Belouze, S. Brood, A. De Truchis, and A. d’AspremontICML25 42nd International Conference on Machine Learning (ICML) 2025Significant efforts have been directed towards adapting self-supervised multimodal learning for Earth observation applications. However, existing methods produce coarse patch-sized embeddings, limiting their effectiveness and integration with other modalities like LiDAR. To close this gap, we present DUNIA, an approach to learn pixel-sized embeddings through cross-modal alignment between images and full-waveform LiDAR data. As the model is trained in a contrastive manner, the embeddings can be directly leveraged in the context of a variety of environmental monitoring tasks in a zero-shot setting. In our experiments, we demonstrate the effectiveness of the embeddings for seven such tasks (canopy height mapping, fractional canopy cover, land cover mapping, tree species identification, plant area index, crop type classification, and per-pixel waveform-based vertical structure mapping). The results show that the embeddings, along with zero-shot classifiers, often outperform specialized supervised models, even in low data regimes. In the fine-tuning setting, we show strong low-shot capabilities with performances near or better than state-of-the-art on five out of six tasks.
@inproceedings{fayad2025dunia, title = {DUNIA: Pixel-Sized Embeddings via Cross-Modal Alignment for Earth Observation Applications}, author = {Fayad, Ibrahim and Zimmer, Max and Schwartz, Martin and Ciais, Philippe and Gieseke, Fabian and Belouze, Gabriel and Brood, Sarah and De Truchis, Aurelien and d'Aspremont, Alexandre}, booktitle = {42nd International Conference on Machine Learning (ICML)}, year = {2025}, tags = {ml,application}, projects = {ai4forest} } -
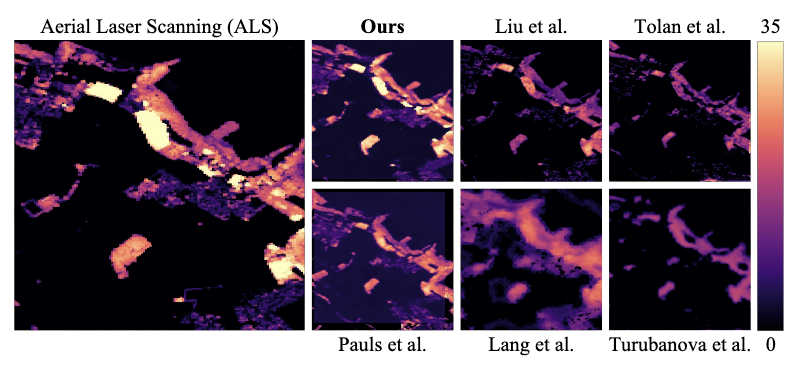 J. Pauls, M. Zimmer, B. Turan, S. Saatchi, P. Ciais, S. Pokutta, and F. GiesekeICML25 42nd International Conference on Machine Learning (ICML) 2025
J. Pauls, M. Zimmer, B. Turan, S. Saatchi, P. Ciais, S. Pokutta, and F. GiesekeICML25 42nd International Conference on Machine Learning (ICML) 2025With the rise in global greenhouse gas emissions, accurate large-scale tree canopy height maps are essential for understanding forest structure, estimating above-ground biomass, and monitoring ecological disruptions. To this end, we present a novel approach to generate large-scale, high-resolution canopy height maps over time. Our model accurately predicts canopy height over multiple years given Sentinel-2 time series satellite data. Using GEDI LiDAR data as the ground truth for training the model, we present the first 10m resolution temporal canopy height map of the European continent for the period 2019-2022. As part of this product, we also offer a detailed canopy height map for 2020, providing more precise estimates than previous studies. Our pipeline and the resulting temporal height map are publicly available, enabling comprehensive large-scale monitoring of forests and, hence, facilitating future research and ecological analyses. For an interactive viewer, see this https URL.
@inproceedings{pauls2025capturing, title = {Capturing Temporal Dynamics in Large-Scale Canopy Tree Height Estimation}, author = {Pauls, Jan and Zimmer, Max and Turan, Berkant and Saatchi, Sassan and Ciais, Philippe and Pokutta, Sebastian and Gieseke, Fabian}, booktitle = {42nd International Conference on Machine Learning (ICML)}, year = {2025}, custom = {Earth Engine|https://europetreemap.projects.earthengine.app/view/temporalcanopyheight}, tags = {ml, application}, projects = {ai4forest} } - M. Schwartz, P. Ciais, E. Sean, A. de Truchis, C. Vega, N. Besic, I. Fayad, J. Wigneron, S. Brood, A. Pelissier-Tanon, J. Pauls, G. Belouze, and Y. XuRemote Sensing of Environment 2025
High-resolution mapping of forest attributes is crucial for ecosystem monitoring and carbon budget assessments. Recent advancements have leveraged satellite imagery and deep learning algorithms to generate high-resolution forest height maps. While these maps provide valuable snapshots of forest conditions, they lack the temporal resolution to estimate forest-related carbon fluxes or track annual changes. Few studies have produced annual forest height, volume, or biomass change maps validated at the forest stand level. To address this limitation, we developed a deep learning framework, coupling data from Sentinel-1 (S1), Sentinel-2 (S2) and from the Global Ecosystem Dynamics Investigation (GEDI) mission, to generate a time series of forest height, growing stock volume, and aboveground biomass at 10 to 30-m spatial resolution that we refer to as FORMS-T (FORest Multiple Satellite Time series). Unlike previous studies, we train our model on individual S2 scenes, rather than on growing season composites, to account for acquisition variability and improve generalization across years. We produced these maps for France over seven years (2018–2024) for height at 10 m resolution and further converted them to 30 m maps of growing stock volume and aboveground biomass using leaf type-specific allometric equations. Evaluation against the French National Forest Inventory (NFI) showed an average mean absolute error of 3.07 m for height (r2=0.68) across all years, 86 m3 ha-1 for volume and 65.1 Mg ha-1 for biomass. We further evaluated FORMS-T capacity to capture growth on a site where two successive airborne laser scanning (ALS) campaigns were available, showing a good agreement with ALS data when aggregating at coarser spatial resolution (r2=0.60, MAE=0.27 m for the 2020–2022 growth of trees between 10 and 15 m in 5 km pixels). Additionally, we compared our results to the NFI-based wood volume production at regional level and obtained a good agreement with a MAE of 1.45 m3 ha-1 yr-1 and r2 of 0.59. We then leveraged our height change maps to derive species-specific growth curves and compared them to ground-based measurements, highlighting distinct growth dynamics and regional variations in forest management practices. Further development of such maps could contribute to the assessment of forest-related carbon stocks and fluxes, contributing to the formulation of a comprehensive carbon budget at the country scale, and supporting global efforts to mitigate climate change.
-
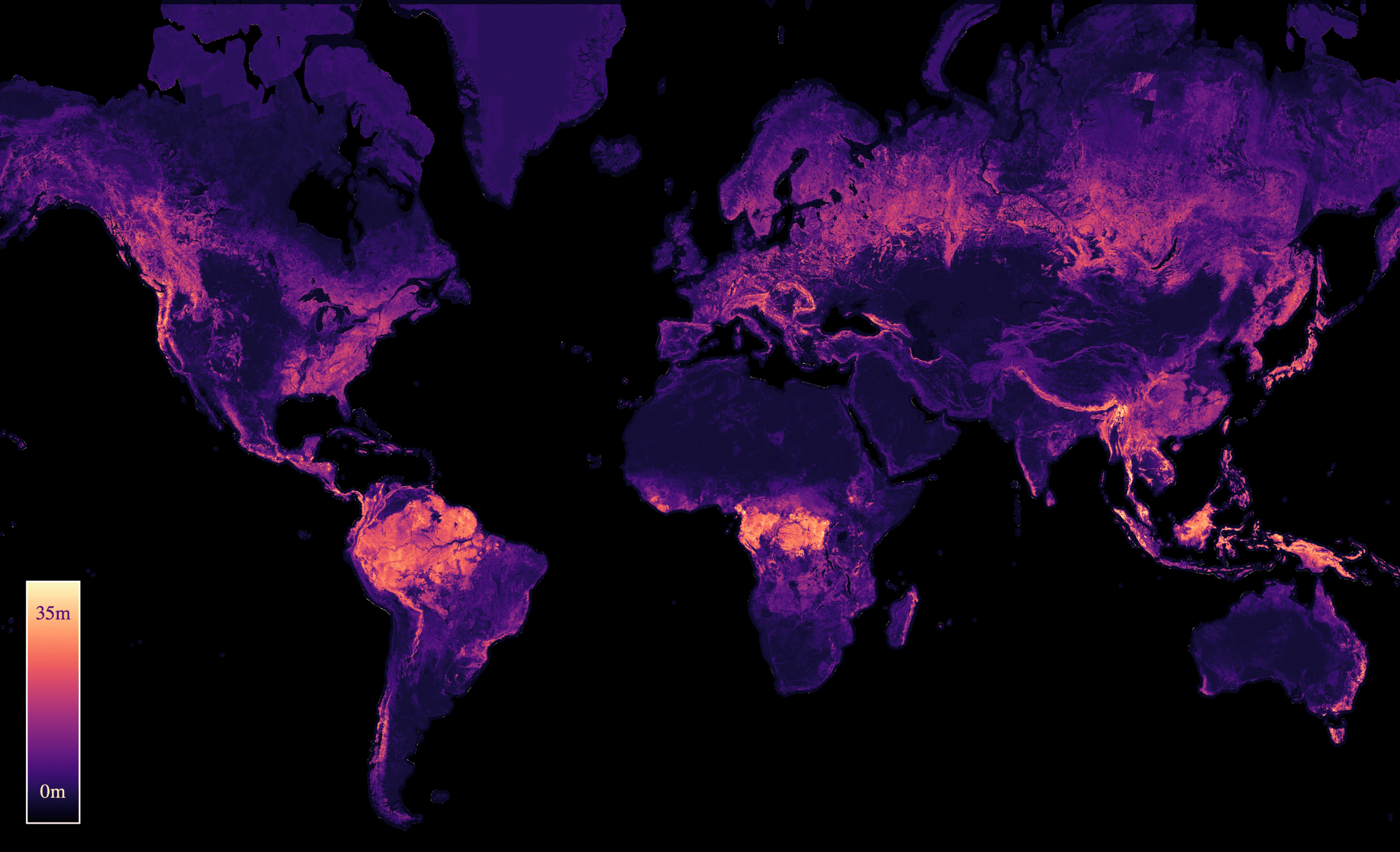 J. Pauls, M. Zimmer, U. M. Kelly, M. Schwartz, S. Saatchi, P. Ciais, S. Pokutta, M. Brandt, and F. GiesekeICML24 41st International Conference on Machine Learning (ICML) 2024
J. Pauls, M. Zimmer, U. M. Kelly, M. Schwartz, S. Saatchi, P. Ciais, S. Pokutta, M. Brandt, and F. GiesekeICML24 41st International Conference on Machine Learning (ICML) 2024We propose a framework for global-scale canopy height estimation based on satellite data. Our model leverages advanced data preprocessing techniques, resorts to a novel loss function designed to counter geolocation inaccuracies inherent in the ground-truth height measurements, and employs data from the Shuttle Radar Topography Mission to effectively filter out erroneous labels in mountainous regions, enhancing the reliability of our predictions in those areas. A comparison between predictions and ground-truth labels yields an MAE / RMSE of 2.43 / 4.73 (meters) overall and 4.45 / 6.72 (meters) for trees taller than five meters, which depicts a substantial improvement compared to existing global-scale maps. The resulting height map as well as the underlying framework will facilitate and enhance ecological analyses at a global scale, including, but not limited to, large-scale forest and biomass monitoring.
@inproceedings{pauls2024estimating, title = {Estimating Canopy Height at Scale}, author = {Pauls, Jan and Zimmer, Max and Kelly, Una M. and Schwartz, Martin and Saatchi, Sassan and Ciais, Philippe and Pokutta, Sebastian and Brandt, Martin and Gieseke, Fabian}, booktitle = {41st International Conference on Machine Learning (ICML)}, year = {2024}, custom = {Earth Engine|https://worldwidemap.projects.earthengine.app/view/canopy-height-2020}, tags = {ml,de,application}, projects = {ai4forest} } -
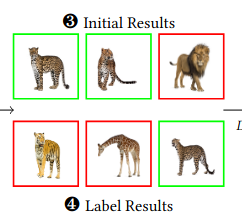 C. Lülf, D. M. Lima Martins, S. M. A. Vaz, Y. Zhou, and F. GiesekeSIGIR24 Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (Demo Track) 2024
C. Lülf, D. M. Lima Martins, S. M. A. Vaz, Y. Zhou, and F. GiesekeSIGIR24 Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (Demo Track) 2024The advent of text-image models, most notably CLIP, has signifi- cantly transformed the landscape of information retrieval. These models enable the fusion of various modalities, such as text and images. One significant outcome of CLIP is its capability to allow users to search for images using text as a query, as well as vice versa. This is achieved via a joint embedding of images and text data that can, for instance, be used to search for similar items. De- spite efficient query processing techniques such as approximate nearest neighbor search, the results may lack precision and com- pleteness. We introduce CLIP-Branches, a novel text-image search engine built upon the CLIP architecture. Our approach enhances traditional text-image search engines by incorporating an interac- tive fine-tuning phase, which allows the user to further concretize the search query by iteratively defining positive and negative exam- ples. Our framework involves training a classification model given the additional user feedback and essentially outputs all positively classified instances of the entire data catalog. By building upon re- cent techniques, this inference phase, however, is not implemented by scanning the entire data catalog, but by employing efficient index structures pre-built for the data. Our results show that the fine-tuned results can improve the initial search outputs in terms of relevance and accuracy while maintaining swift response times
@inproceedings{LuelfLMVZG2024CLIPBranches, author = {Lülf, Christian and {Lima Martins}, Denis Mayr and Vaz, Salles Marcos Antonio and Zhou, Yongluan and Gieseke, Fabian}, title = {CLIP-Branches: Interactive Fine-Tuning for Text-Image Retrieval}, booktitle = {Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (Demo Track)}, year = {2024}, address = {Washington, D.C.}, tags = {ml,de}, } -
 S. Oehmcke, L. Li, K. Trepekli, J. C. Revenga, T. Nord-Larsen, F. Gieseke, and C. IgelJOURNALRemote Sensing of Environment 2024
S. Oehmcke, L. Li, K. Trepekli, J. C. Revenga, T. Nord-Larsen, F. Gieseke, and C. IgelJOURNALRemote Sensing of Environment 2024Quantifying forest biomass stocks and their dynamics is important for implementing effective climate change mitigation measures by aiding local forest management, studying processes driving af-, re-, and deforestation, and improving the accuracy of carbon accounting. Owing to the 3-dimensional nature of forest structure, remote sensing using airborne LiDAR can be used to perform these measurements of vegetation structure at large scale. Harnessing the full dimensionality of the data, we present deep learning systems predicting wood volume and above ground biomass (AGB) directly from the full LiDAR point cloud and compare results to state-of-the-art approaches operating on basic statistics of the point clouds. For this purpose, we devise different neural network architectures for point cloud regression and evaluate them on remote sensing data of areas for which AGB estimates have been obtained from field measurements in the Danish national forest inventory. Our adaptation of Minkowski convolutional neural networks for regression give the best results. The deep neural networks produce significantly more accurate wood volume, AGB, and carbon stock estimates compared to state-of-the-art approaches. In contrast to other methods, the proposed deep learning approach does not require a digital terrain model and is robust to artifacts along the boundaries of the evaluated areas, which we demonstrate for the case where trees protrude into the area from the outside. We expect this finding to have a strong impact on LiDAR-based analyses of biomass dynamics.
@article{OehmckeLTRNLGI2024DeepPointCloud, author = {Oehmcke, Stefan and Li, Lei and Trepekli, Katerina and Revenga, Jaime C. and Nord-Larsen, Thomas and Gieseke, Fabian and Igel, Christian}, title = {Deep point cloud regression for above-ground forest biomass estimation from airborne LiDAR}, journal = {Remote Sensing of Environment}, year = {2024}, volume = {302}, doi = {10.1016/j.rse.2023.113968}, tags = {rs,ml,application} } -
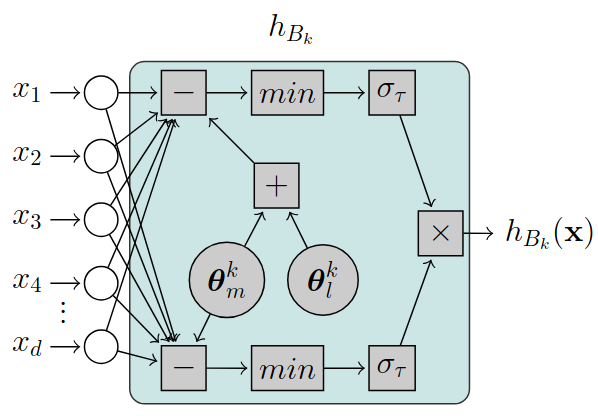 D. L. M. Martins, C. Lülf, and F. GiesekeESANN23 31st European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning 2023
D. L. M. Martins, C. Lülf, and F. GiesekeESANN23 31st European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning 2023Hyperbox-based classification has been seen as a promising technique in which decisions on the data are represented as a series of orthogonal, multidimensional boxes (i.e., hyperboxes) that are often interpretable and human-readable. However, existing methods are no longer capable of efficiently handling the increasing volume of data many application domains face nowadays. We address this gap by proposing a novel, fully differentiable framework for hyperbox-based classification via neural networks. In contrast to previous work, our hyperbox models can be efficiently trained in an end-to-end fashion, which leads to significantly reduced training times and superior classification results.
@inproceedings{LimaDCF2023EndToEndNeural, author = {Martins, Denis Lima Mayr and Lülf, Christian and Gieseke, Fabian}, title = {End-to-End Neural Network Training for Hyperbox-Based Classification}, booktitle = {31st European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning}, year = {2023}, address = {Brügge}, tags = {ml} } -
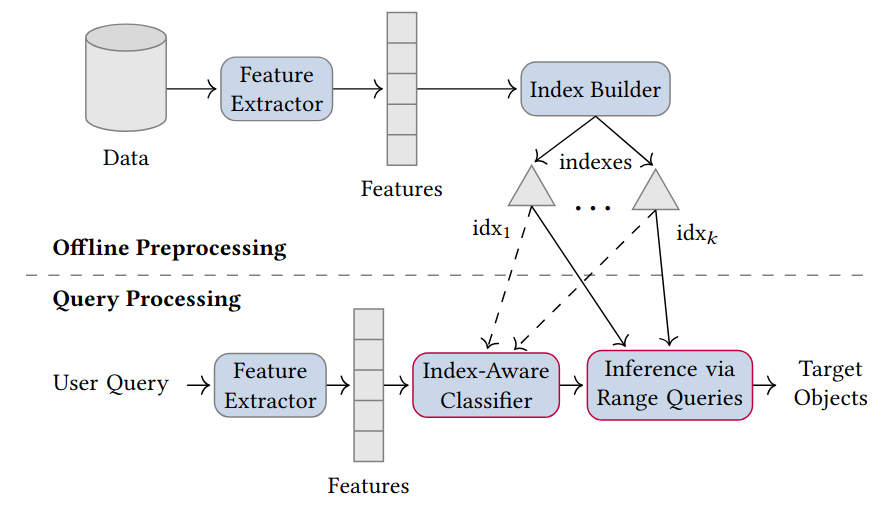 C. Lülf, D. M. Lima Martins, S. M. A. Vaz, Y. Zhou, and F. GiesekeVLDB23 Proceedings of the VLDB Endowment 2023
C. Lülf, D. M. Lima Martins, S. M. A. Vaz, Y. Zhou, and F. GiesekeVLDB23 Proceedings of the VLDB Endowment 2023The vast amounts of data collected in various domains pose great challenges to modern data exploration and analysis. To find “inter- esting” objects in large databases, users typically define a query using positive and negative example objects and train a classifi- cation model to identify the objects of interest in the entire data catalog. However, this approach requires a scan of all the data to apply the classification model to each instance in the data catalog, making this method prohibitively expensive to be employed in large-scale databases serving many users and queries interactively. In this work, we propose a novel framework for such search-by- classification scenarios that allows users to interactively search for target objects by specifying queries through a small set of positive and negative examples. Unlike previous approaches, our frame- work can rapidly answer such queries at low cost without scanning the entire database. Our framework is based on an index-aware construction scheme for decision trees and random forests that transforms the inference phase of these classification models into a set of range queries, which in turn can be efficiently executed by leveraging multidimensional indexing structures. Our experiments show that queries over large data catalogs with hundreds of millions of objects can be processed in a few seconds using a single server, compared to hours needed by classical scanning-based approaches.
@inproceedings{LuelfLMVZG2023FastSearchByClassification, author = {Lülf, Christian and {Lima Martins}, Denis Mayr and Vaz, Salles Marcos Antonio and Zhou, Yongluan and Gieseke, Fabian}, title = {Fast Search-By-Classification for Large-Scale Databases Using Index-Aware Decision Trees and Random Forests}, booktitle = {Proceedings of the VLDB Endowment}, pages = {2845--2857}, volume = {16}, editor = {VLDB, Endowment}, year = {2023}, publisher = {ACM Press}, address = {Vancouver}, issn = {2150-8097}, doi = {10.14778/3611479.3611492}, tags = {ml,de} } -
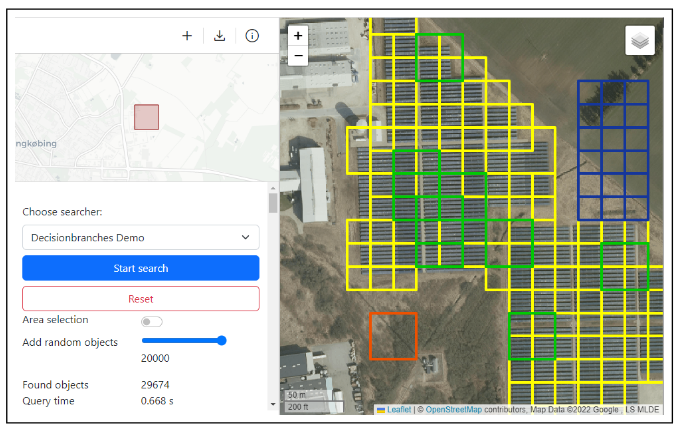 RapidEarth: A Search Engine for Large-Scale Geospatial Imagery Best Demo AwardC. Lülf, D. M. Lima Martins, S. M. A. Vaz, Y. Zhou, and F. GiesekeSIGSPATIAL23 Proceedings of the 31st International Conference on Advances in Geographic Information Systems, SIGSPATIAL, Demo Paper, 2023 (Best Demo Award) 2023
RapidEarth: A Search Engine for Large-Scale Geospatial Imagery Best Demo AwardC. Lülf, D. M. Lima Martins, S. M. A. Vaz, Y. Zhou, and F. GiesekeSIGSPATIAL23 Proceedings of the 31st International Conference on Advances in Geographic Information Systems, SIGSPATIAL, Demo Paper, 2023 (Best Demo Award) 2023Data exploration and analysis in various domains often necessitate the search for specific objects in massive databases. A common search strategy, often known as search-by-classification, resorts to training machine learning models on small sets of positive and negative samples and to performing inference on the entire database to discover additional objects of interest. While such an approach often yields very good results in terms of classification performance, the entire database usually needs to be scanned, a process that can easily take several hours even for medium-sized data catalogs. In this work, we present RapidEarth, a geospatial search-by-classification engine that allows analysts to rapidly search for interesting objects in very large data collections of satellite imagery in a matter of seconds, without the need to scan the entire data catalog. RapidEarth embodies a co-design of multidimensional indexing structures and decision branches, a recently proposed variant of classical decision trees. These decision branches allow RapidEarth to transform the inference phase into a set of range queries, which can be efficiently processed by leveraging the aforementioned multidimensional indexing structures. The main contribution of this work is a geospatial search engine that implements these technical findings.
-
 S. Li, M. Brandt, R. Fensholt, A. Kariryaa, C. Igel, F. Gieseke, T. Nord-Larsen, S. Oehmcke, A. H. Carlsen, S. Junttila, X. Tong, A. d’Aspremont, and P. CiaisJOURNALPNAS Nexus 2023
S. Li, M. Brandt, R. Fensholt, A. Kariryaa, C. Igel, F. Gieseke, T. Nord-Larsen, S. Oehmcke, A. H. Carlsen, S. Junttila, X. Tong, A. d’Aspremont, and P. CiaisJOURNALPNAS Nexus 2023Sustainable tree resource management is the key to mitigating climate warming, fostering a green economy, and protecting valuable habitats. Detailed knowledge about tree resources is a prerequisite for such management but is conventionally based on plot-scale data, which often neglects trees outside forests. Here, we present a deep learning-based framework that provides location, crown area, and height for individual overstory trees from aerial images at country scale. We apply the framework on data covering Denmark and show that large trees (stem diameter >10 cm) can be identified with a low bias (12.5%) and that trees outside forests contribute to 30% of the total tree cover, which is typically unrecognized in national inventories. The bias is high (46.6%) when our results are evaluated against all trees taller than 1.3 m, which involve undetectable small or understory trees. Furthermore, we demonstrate that only marginal effort is needed to transfer our framework to data from Finland, despite markedly dissimilar data sources. Our work lays the foundation for digitalized national databases, where large trees are spatially traceable and manageable.
@article{LiSMRACFTSASXAP2023DeepLearning, author = {Li, Sizhuo and Brandt, Martin and Fensholt, Rasmus and Kariryaa, Ankit and Igel, Christian and Gieseke, Fabian and Nord-Larsen, Thomas and Oehmcke, Stefan and Carlsen, Ask Holm and Junttila, Samuli and Tong, Xiaoye and d’Aspremont, Alexandre and Ciais, Philippe}, title = {Deep learning enables image-based tree counting, crown segmentation, and height prediction at national scale}, journal = {PNAS Nexus}, year = {2023}, volume = {2}, number = {4}, doi = {10.1093/pnasnexus/pgad076}, tags = {rs,application,ml} } -
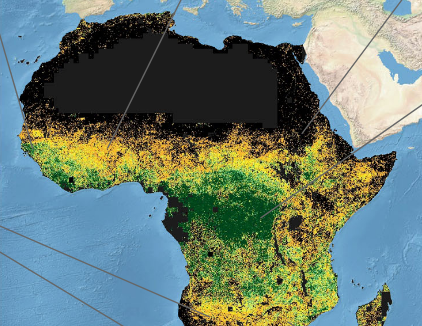 F. Reiner, M. Brandt, X. Tong, D. Skole, A. Kariryaa, P. Ciais, A. Davies, P. Hiernaux, J. Chave, M. Mugabowindekwe, C. Igel, S. Oehmcke, F. Gieseke, S. Li, S. Liu, S. S. Saatchi, P. Boucher, J. Singh, S. Taugourdeau, M. Dendoncker, X. Song, O. Mertz, C. Tucker, and R. FensholtJOURNALNature Communications 2023
F. Reiner, M. Brandt, X. Tong, D. Skole, A. Kariryaa, P. Ciais, A. Davies, P. Hiernaux, J. Chave, M. Mugabowindekwe, C. Igel, S. Oehmcke, F. Gieseke, S. Li, S. Liu, S. S. Saatchi, P. Boucher, J. Singh, S. Taugourdeau, M. Dendoncker, X. Song, O. Mertz, C. Tucker, and R. FensholtJOURNALNature Communications 2023The consistent monitoring of trees both inside and outside of forests is key to sustainable land management. Current monitoring systems either ignore trees outside forests or are too expensive to be applied consistently across countries on a repeated basis. Here we use the PlanetScope nanosatellite constellation, which delivers global very high-resolution daily imagery, to map both forest and non-forest tree cover for continental Africa using images from a single year. Our prototype map of 2019 (RMSE = 9.57%, bias = −6.9%). demonstrates that a precise assessment of all tree-based ecosystems is possible at continental scale, and reveals that 29% of tree cover is found outside areas previously classified as tree cover in state-of-the-art maps, such as in croplands and grassland. Such accurate mapping of tree cover down to the level of individual trees and consistent among countries has the potential to redefine land use impacts in non-forest landscapes, move beyond the need for forest definitions, and build the basis for natural climate solutions and tree-related studies.
@article{ReinerBTSKCDHCMIOGLLSBSTDSMTF2023MoreThanOne, author = {Reiner, Florian and Brandt, Martin and Tong, Xiaoye and Skole, David and Kariryaa, Ankit and Ciais, Philippe and Davies, Andrew and Hiernaux, Pierre and Chave, Jerome and Mugabowindekwe, Maurice and Igel, Christian and Oehmcke, Stefan and Gieseke, Fabian and Li, Sizhuo and Liu, Siyu and Saatchi, Sassan S and Boucher, Peter and Singh, Jenia and Taugourdeau, Simon and Dendoncker, Morgane and Song, Xiao-Peng and Mertz, Ole and Tucker, Compton and Fensholt, Rasmus}, title = {More than one quarter of Africa's tree cover is found outside areas previously classified as forest}, journal = {Nature Communications}, year = {2023}, tags = {rs,application,ml} } -
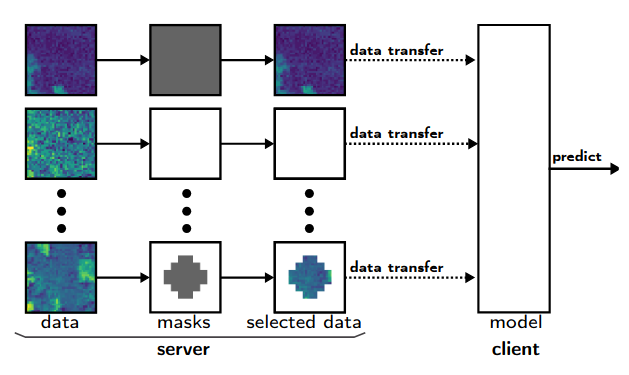 S. Oehmcke, and F. GiesekeSDM22 Proceedings of the 2022 SIAM International Conference on Data Mining (SDM) 2022
S. Oehmcke, and F. GiesekeSDM22 Proceedings of the 2022 SIAM International Conference on Data Mining (SDM) 2022Data are often accommodated on centralized storage servers. This is the case, for instance, in remote sensing and astronomy, where projects produce several petabytes of data every year. While machine learning models are often trained on relatively small subsets of the data, the inference phase typically requires transferring significant amounts of data between the servers and the clients. In many cases, the bandwidth available per user is limited, which then renders the data transfer to be one of the major bottlenecks. In this work, we propose a framework that automatically selects the relevant parts of the input data for a given neural network. The model as well as the associated selection masks are trained simultaneously such that a good model performance is achieved while only a minimal amount of data is selected. During the inference phase, only those parts of the data have to be transferred between the server and the client. We propose both instance-independent and instance-dependent selection masks. The former ones are the same for all instances to be transferred, whereas the latter ones allow for variable transfer sizes per instance. Our experiments show that it is often possible to significantly reduce the amount of data needed to be transferred without affecting the model quality much.
@inproceedings{OehmckeG2022InputSelection, author = {Oehmcke, Stefan and Gieseke, Fabian}, title = {Input Selection for Bandwidth-Limited Neural Network Inference}, booktitle = {Proceedings of the 2022 SIAM International Conference on Data Mining (SDM)}, pages = {280--288}, editor = {Banerjee, Arindam and Zhou, Zhi-Hua and Papalexakis, Evangelos E. and Riondato, Matteo}, year = {2022}, publisher = {SIAM Publications}, address = {USA}, doi = {10.1137/1.9781611977172.32}, tags = {ml,de}, } -
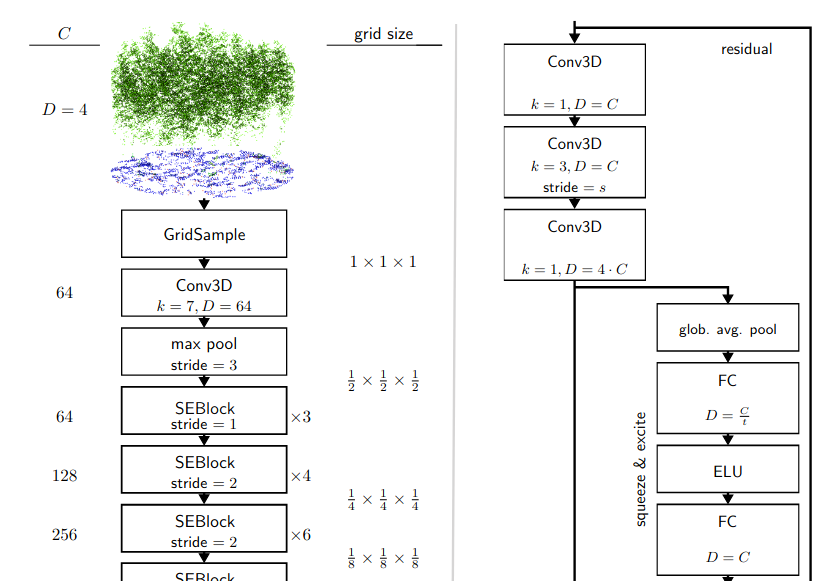 S. Oehmcke, L. Li, J. Revenga, T. Nord-Larsen, K. Trepekli, F. Gieseke, and C. IgelSIGSPATIAL22 30th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems (ACM SIGSPATIAL 2022) 2022
S. Oehmcke, L. Li, J. Revenga, T. Nord-Larsen, K. Trepekli, F. Gieseke, and C. IgelSIGSPATIAL22 30th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems (ACM SIGSPATIAL 2022) 2022Quantification of forest biomass stocks and their dynamics is important for implementing effective climate change mitigation measures. The knowledge is needed, e.g., for local forest management, studying the processes driving af-, re-, and deforestation, and can improve the accuracy of carbon-accounting. Remote sensing using airborne LiDAR can be used to perform these measurements of vegetation structure at large scale. We present deep learning systems for predicting wood volume, above-ground biomass (AGB), and subsequently above-ground carbon stocks directly from airborne LiDAR point clouds. We devise different neural network architectures for point cloud regression and evaluate them on remote sensing data of areas for which AGB estimates have been obtained from field measurements in the Danish national forest inventory. Our adaptation of Minkowski convolutional neural networks for regression gave the best results. The deep neural networks produced significantly more accurate wood volume, AGB, and carbon stock estimates compared to state-of-the-art approaches operating on basic statistics of the point clouds. In contrast to other methods, the proposed deep learning approach does not require a digital terrain model. We expect this finding to have a strong impact on LiDAR-based analyses of biomass dynamics.
@inproceedings{OehmckeLRNLTGI2022DeepLearning, author = {Oehmcke, Stefan and Li, Lei and Revenga, Jaime and Nord-Larsen, Thomas and Trepekli, Katerina and Gieseke, Fabian and Igel, Christian}, title = {Deep Learning Based 3D Point Cloud Regression for Estimating Forest Biomass}, booktitle = {30th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems (ACM SIGSPATIAL 2022)}, pages = {1--4}, editor = {Renz, Matthias and Sarwat, Mohamed}, year = {2022}, publisher = {ACM Press}, address = {New York, NY, USA}, doi = {10.1145/3557915.3561471}, tags = {ml,application,rs} } -
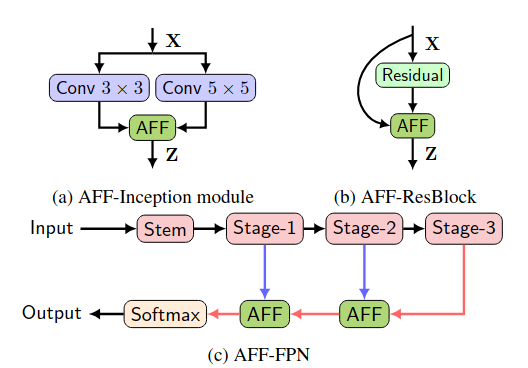 Y. Dai, F. Gieseke, S. Oehmcke, Y. Wu, and K. BarnardWACV21 Proceedings of the Workshop on Applications of Computer Vision (WACV) 2021
Y. Dai, F. Gieseke, S. Oehmcke, Y. Wu, and K. BarnardWACV21 Proceedings of the Workshop on Applications of Computer Vision (WACV) 2021Feature fusion, the combination of features from different layers or branches, is an omnipresent part of modern network architectures. It is often implemented via simple operations, such as summation or concatenation, but this might not be the best choice. In this work, we propose a uniform and general scheme, namely attentional feature fusion, which is applicable for most common scenarios, including feature fusion induced by short and long skip connections as well as within Inception layers. To better fuse features of inconsistent semantics and scales, we propose a multi-scale channel attention module, which addresses issues that arise when fusing features given at different scales. We also demonstrate that the initial integration of feature maps can become a bottleneck and that this issue can be alleviated by adding another level of attention, which we refer to as iterative attentional feature fusion. With fewer layers or parameters, our models outperform state-of-the-art networks on both CIFAR-100 and ImageNet datasets, which suggests that more sophisticated attention mechanisms for feature fusion hold great potential to consistently yield better results compared to their direct counterparts. Our codes and trained models are available online.
@inproceedings{DaiGOWB2021Attentional, author = {Dai, Yimian and Gieseke, Fabian and Oehmcke, Stefan and Wu, Yiquan and Barnard, Kobus}, title = {Attentional Feature Fusion}, booktitle = {Proceedings of the Workshop on Applications of Computer Vision (WACV)}, pages = {3559--3568}, year = {2021}, publisher = {IEEE}, doi = {10.1109/WACV48630.2021.00360}, tags = {ml}, } -
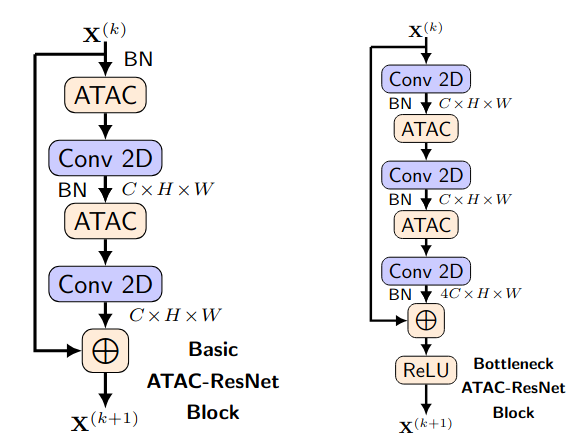 Y. Dai, S. Oehmcke, F. Gieseke, Y. Wu, and K. BarnardICPR20 Proceedings of the 25th International Conference on Pattern Recognition (ICPR) 2020
Y. Dai, S. Oehmcke, F. Gieseke, Y. Wu, and K. BarnardICPR20 Proceedings of the 25th International Conference on Pattern Recognition (ICPR) 2020@inproceedings{DaiOGWB2020AttentionAs, author = {Dai, Yimian and Oehmcke, Stefan and Gieseke, Fabian and Wu, Yiquan and Barnard, Kobus}, title = {Attention as Activation}, booktitle = {Proceedings of the 25th International Conference on Pattern Recognition (ICPR)}, pages = {9156--9163}, year = {2020}, publisher = {IEEE}, address = {Milan, Italy}, doi = {10.1109/ICPR48806.2021.9413020}, tags = {ml}, } -
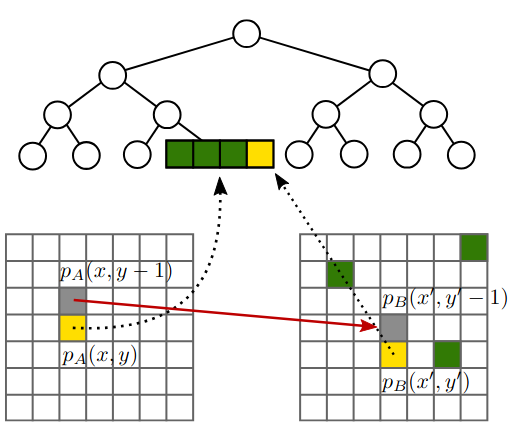 C. E. Oancea, T. Robroek, and F. GiesekeIEEE BIGDATA 2020 2020 IEEE International Conference on Big Data 2020
C. E. Oancea, T. Robroek, and F. GiesekeIEEE BIGDATA 2020 2020 IEEE International Conference on Big Data 2020Nearest neighbour fields accurately and intuitively describe the transformation between two images and have been heavily used in computer vision. Generating such fields, however, is not an easy task due to the induced computational complexity, which quickly grows with the sizes of the images. Modern parallel devices such as graphics processing units depict a viable way of reducing the practical run time of such compute-intensive tasks. In this work, we propose a novel parallel implementation for one of the state-of-the-art methods for the computation of nearest neighbour fields, called p ropagation-assisted k -d trees. The resulting implementation yields valuable computational savings over a corresponding multi-core implementation. Additionally, it is tuned to consume only little additional memory and is, hence, capable of dealing with high-resolution image data, which is vital as image quality standards keep rising.
@inproceedings{OanceaRG2020Approximate, author = {Oancea, Cosmin Eugen and Robroek, Ties and Gieseke, Fabian}, title = {Approximate Nearest-Neighbour Fields via Massively-Parallel Propagation-Assisted K-D Trees}, booktitle = {2020 {IEEE} International Conference on Big Data}, pages = {5172--5181}, year = {2020}, publisher = {IEEE}, doi = {10.1109/BigData50022.2020.9378426}, tags = {de,ml}, } -
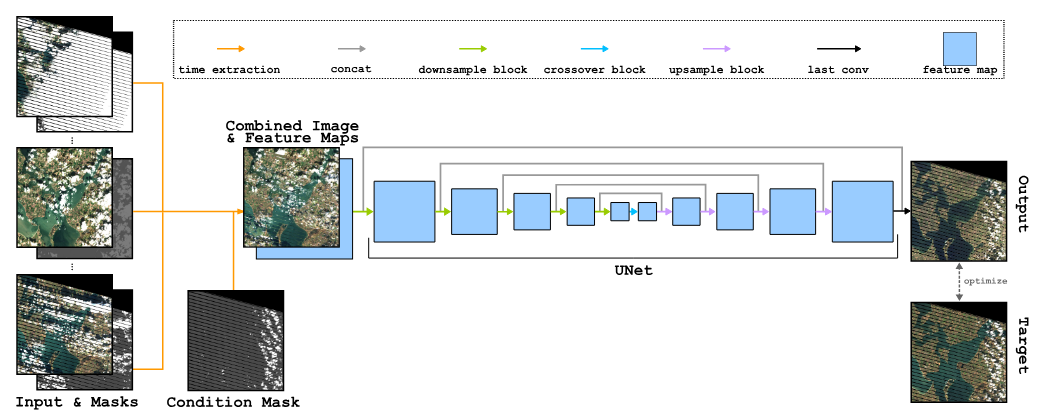 S. Oehmcke, T. K. Chen, A. V. Prishchepov, and F. GiesekeBIGSPATIAL20 Proceedings of the 9th ACM SIGSPATIAL International Workshop on Analytics for Big Geospatial Data 2020
S. Oehmcke, T. K. Chen, A. V. Prishchepov, and F. GiesekeBIGSPATIAL20 Proceedings of the 9th ACM SIGSPATIAL International Workshop on Analytics for Big Geospatial Data 2020Optical satellite images are important for environmental monitoring. Unfortunately, such images are often affected by distortions, such as clouds, shadows, or missing data. This work proposes a deep learning approach for cleaning and imputing satellite images, which could serve as a reliable preprocessing step for spatial and spatio-temporal analyzes. More specifically, a coherent and cloud-free image for a specific target date and region is created based on a sequence of images of that region obtained at previous dates. Our model first extracts information from the previous time steps via a special gating function and then resorts to a modified version of the well-known U-Net architecture to obtain the desired output image. The model uses supplementary data, namely the approximate cloud coverage of input images, the temporal distance to the target time, and a missing data mask for each input time step. During the training phase we condition our model with the targets cloud coverage and missing values (disabled in production), which allows us to use data afflicted by distortion during training and thus does not require pre-selection of distortion-free data. Our experimental evaluation, conducted on data of the Landsat missions, shows that our approach outperforms the commonly utilized approach that resorts to taking the median of cloud-free pixels for a given position. This is especially the case when the quality of the data for the considered period is poor (e.g., lack of cloud free-images during the winter/fall periods). Our deep learning approach allows to improve the utility of the entire Landsat archive, the only existing global medium-resolution free-access satellite archive dating back to the 1970s. It therefore holds scientific and societal potential for future analyses conducted on data from this and other satellite imagery repositories.
@inproceedings{OehmckeTHPG2020CreatingCloudFree, author = {Oehmcke, Stefan and Chen, Tzu-Hsin Karen and Prishchepov, Alexander V. and Gieseke, Fabian}, title = {Creating Cloud-Free Satellite Imagery from Image Time Series with Deep Learning}, booktitle = {Proceedings of the 9th ACM SIGSPATIAL International Workshop on Analytics for Big Geospatial Data}, pages = {3:1-3:10}, year = {2020}, publisher = {ACM}, address = {Seattle, USA}, doi = {10.1145/3423336.3429345}, tags = {ml,de,rs,application}, } -
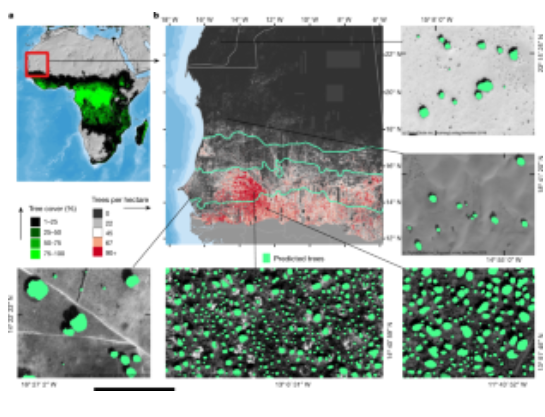 M. Brandt, C. Tucker, A. Kariryaa, K. Rasmussen, C. Abel, J. Small, J. Chave, L. Rasmussen, P. Hiernaux, A. Diouf, L. Kergoat, O. Mertz, C. Igel, F. Gieseke, J. Schöning, S. Li, K. Melocik, J. Meyer, SinnoS, E. Romero, E. Glennie, A. Montagu, M. Dendoncker, and R. FensholtJOURNALNature 2020
M. Brandt, C. Tucker, A. Kariryaa, K. Rasmussen, C. Abel, J. Small, J. Chave, L. Rasmussen, P. Hiernaux, A. Diouf, L. Kergoat, O. Mertz, C. Igel, F. Gieseke, J. Schöning, S. Li, K. Melocik, J. Meyer, SinnoS, E. Romero, E. Glennie, A. Montagu, M. Dendoncker, and R. FensholtJOURNALNature 2020A large proportion of dryland trees and shrubs (hereafter referred to collectively as trees) grow in isolation, without canopy closure. These non-forest trees have a crucial role in biodiversity, and provide ecosystem services such as carbon storage, food resources and shelter for humans and animals. However, most public interest relating to trees is devoted to forests, and trees outside of forests are not well-documented. Here we map the crown size of each tree more than 3 m2 in size over a land area that spans 1.3 million km2 in the West African Sahara, Sahel and sub-humid zone, using submetre-resolution satellite imagery and deep learning. We detected over 1.8 billion individual trees (13.4 trees per hectare), with a median crown size of 12 m2, along a rainfall gradient from 0 to 1,000 mm per year. The canopy cover increases from 0.1% (0.7 trees per hectare) in hyper-arid areas, through 1.6% (9.9 trees per hectare) in arid and 5.6% (30.1 trees per hectare) in semi-arid zones, to 13.3% (47 trees per hectare) in sub-humid areas. Although the overall canopy cover is low, the relatively high density of isolated trees challenges prevailing narratives about dryland desertification, and even the desert shows a surprisingly high tree density. Our assessment suggests a way to monitor trees outside of forests globally, and to explore their role in mitigating degradation, climate change and poverty.
@article{BrandtTKRASCRHDKMIGSLMMSRGMDF2020AnUnexpectedly, author = {Brandt, M and Tucker, C and Kariryaa, A and Rasmussen, K and Abel, C and Small, J and Chave, J and Rasmussen, L and Hiernaux, P and Diouf, A and Kergoat, L and Mertz, O and Igel, C and Gieseke, F and Schöning, J and Li, S and Melocik, K and Meyer, J and SinnoS and Romero, E and Glennie, E and Montagu, A and Dendoncker, M and Fensholt, R}, title = {An unexpectedly large count of trees in the West African Sahara and Sahel}, journal = {Nature}, year = {2020}, volume = {2020}, doi = {10.1038/s41586-020-2824-5}, tags = {application,rs,ml} } -
 V. Ko, S. Oehmcke, and F. GiesekeIEEE BIGDATA 2019 2019 IEEE International Conference on Big Data (IEEE BigData) 2019
V. Ko, S. Oehmcke, and F. GiesekeIEEE BIGDATA 2019 2019 IEEE International Conference on Big Data (IEEE BigData) 2019Neural networks have achieved dramatic improvements in recent years and depict the state-of-the-art methods for many real-world tasks nowadays. One drawback is, however, that many of these models are overparameterized, which makes them both computationally and memory intensive. Furthermore, overparameterization can also lead to undesired overfitting side-effects. Inspired by recently proposed magnitude-based pruning schemes and the Wald test from the field of statistics, we introduce a novel magnitude and uncertainty (M&U) pruning criterion that helps to lessen such shortcomings. One important advantage of our M&U pruning criterion is that it is scale-invariant, a phenomenon that the magnitude-based pruning criterion suffers from. In addition, we present a “pseudo bootstrap” scheme, which can efficiently estimate the uncertainty of the weights by using their update information during training. Our experimental evaluation, which is based on various neural network architectures and datasets, shows that our new criterion leads to more compressed models compared to models that are solely based on magnitude-based pruning criteria, with, at the same time, less loss in predictive power.
@inproceedings{KoOG2019MagnitudeAnd, author = {Ko, Vinnie and Oehmcke, Stefan and Gieseke, Fabian}, title = {Magnitude and Uncertainty Pruning Criterion for Neural Networks}, booktitle = {2019 {IEEE} International Conference on Big Data {(IEEE} BigData)}, pages = {2317--2326}, year = {2019}, publisher = {IEEE}, address = {Los Angeles, USA}, doi = {10.1109/BigData47090.2019.9005692}, url = {https://doi.org/10.1109/BigData47090.2019.9005692}, tags = {ml}, } -
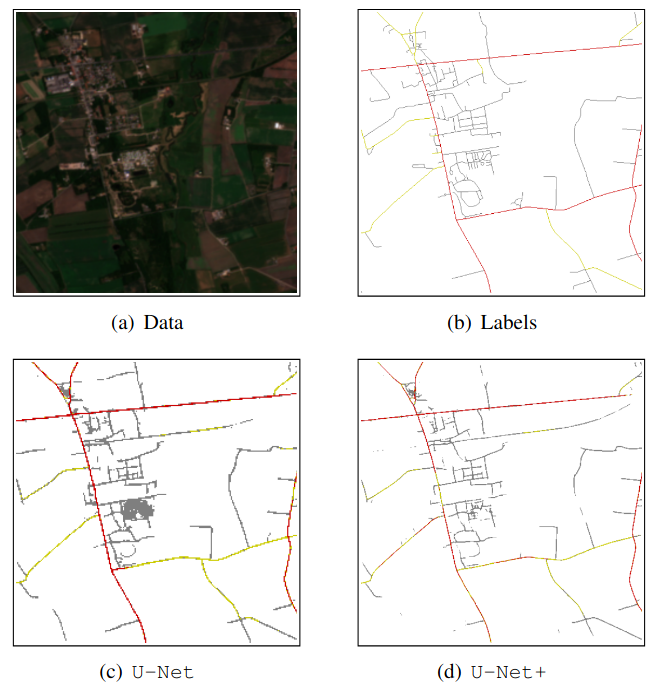 S. Oehmcke, C. Thrysøe, A. Borgstad, M. V. Salles, M. Brandt, and F. GiesekeIEEE BIGDATA 2019 2019 IEEE International Conference on Big Data (IEEE BigData) 2019
S. Oehmcke, C. Thrysøe, A. Borgstad, M. V. Salles, M. Brandt, and F. GiesekeIEEE BIGDATA 2019 2019 IEEE International Conference on Big Data (IEEE BigData) 2019Massive amounts of satellite data have been gathered over time, holding the potential to unveil a spatiotemporal chronicle of the surface of Earth. These data allow scientists to investigate various important issues, such as land use changes, on a global scale. However, not all land-use phenomena are equally visible on satellite imagery. In particular, the creation of an inventory of the planet’s road infrastructure remains a challenge, despite being crucial to analyze urbanization patterns and their impact. Towards this end, this work advances data-driven approaches for the automatic identification of roads based on open satellite data. Given the typical resolutions of these historical satellite data, we observe that there is inherent variation in the visibility of different road types. Based on this observation, we propose two deep learning frameworks that extend state-of-the-art deep learning methods by formalizing road detection as an ordinal classification task. In contrast to related schemes, one of the two models also resorts to satellite time series data that are potentially affected by missing data and cloud occlusion. Taking these time series data into account eliminates the need to manually curate datasets of high-quality image tiles, substantially simplifying the application of such models on a global scale. We evaluate our approaches on a dataset that is based on Sentinel 2 satellite imagery and OpenStreetMap vector data. Our results indicate that the proposed models can successfully identify large and medium-sized roads. We also discuss opportunities and challenges related to the detection of roads and other infrastructure on a global scale.
@inproceedings{OehmckeTBMBG2019DetectingHardly, author = {Oehmcke, Stefan and Thrysøe, Christoph and Borgstad, Andreas and Salles, Marcos Vaz and Brandt, Martin and Gieseke, Fabian}, title = {Detecting Hardly Visible Roads in Low-Resolution Satellite Time Series Data}, booktitle = {2019 {IEEE} International Conference on Big Data {(IEEE} BigData)}, pages = {2403--2412}, year = {2019}, publisher = {IEEE}, doi = {10.1109/BigData47090.2019.9006251}, tags = {ml,application,rs}, } -
 F. Gieseke, and C. IgelKDD18 Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD 2018, London, UK, August 19-23, 2018 2018
F. Gieseke, and C. IgelKDD18 Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD 2018, London, UK, August 19-23, 2018 2018Without access to large compute clusters, building random forests on large datasets is still a challenging problem. This is, in particular, the case if fully-grown trees are desired. We propose a simple yet effective framework that allows to efficiently construct ensembles of huge trees for hundreds of millions or even billions of training instances using a cheap desktop computer with commodity hardware. The basic idea is to consider a multi-level construction scheme, which builds top trees for small random subsets of the available data and which subsequently distributes all training instances to the top trees’ leaves for further processing. While being conceptually simple, the overall efficiency crucially depends on the particular implementation of the different phases. The practical merits of our approach are demonstrated using dense datasets with hundreds of millions of training instances.
@inproceedings{GiesekeI2018TrainingBig, author = {Gieseke, Fabian and Igel, Christian}, title = {Training Big Random Forests with Little Resources}, booktitle = {Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD 2018, London, UK, August 19-23, 2018}, pages = {1445--1454}, year = {2018}, publisher = {ACM}, doi = {10.1145/3219819.3220124}, tags = {ml,de}, } -
 F. Gieseke, S. Bloemen, C. Bogaard, T. Heskes, J. Kindler, R. A. Scalzo, V. A. Ribeiro, J. Roestel, P. J. Groot, F. Yuan, A. Möller, and B. E. TuckerJOURNALMonthly Notices of the Royal Astronomical Society (MNRAS) 2017
F. Gieseke, S. Bloemen, C. Bogaard, T. Heskes, J. Kindler, R. A. Scalzo, V. A. Ribeiro, J. Roestel, P. J. Groot, F. Yuan, A. Möller, and B. E. TuckerJOURNALMonthly Notices of the Royal Astronomical Society (MNRAS) 2017Current synoptic sky surveys monitor large areas of the sky to find variable and transient astronomical sources. As the number of detections per night at a single telescope easily exceeds several thousand, current detection pipelines make intensive use of machine learning algorithms to classify the detected objects and to filter out the most interesting candidates. A number of upcoming surveys will produce up to three orders of magnitude more data, which renders high-precision classification systems essential to reduce the manual and, hence, expensive vetting by human experts. We present an approach based on convolutional neural networks to discriminate between true astrophysical sources and artefacts in reference-subtracted optical images. We show that relatively simple networks are already competitive with state-of-the-art systems and that their quality can further be improved via slightly deeper networks and additional pre-processing steps – eventually yielding models outperforming state-of-the-art systems. In particular, our best model correctly classifies about 97.3 per cent of all ‘real’ and 99.7 per cent of all ‘bogus’ instances on a test set containing 1942 ‘bogus’ and 227 ‘real’ instances in total. Furthermore, the networks considered in this work can also successfully classify these objects at hand without relying on difference images, which might pave the way for future detection pipelines not containing image subtraction steps at all.
@article{GiesekeEtAl2017, author = {Gieseke, Fabian and Bloemen, Steven and van den Bogaard, Cas and Heskes, Tom and Kindler, Jonas and Scalzo, Richard A. and Ribeiro, Valerio A.R.M. and van Roestel, Jan and Groot, Paul J. and Yuan, Fang and Möller, Anais and Tucker, Brad E.}, title = {Convolutional Neural Networks for Transient Candidate Vetting in Large-Scale Surveys}, journal = {Monthly Notices of the Royal Astronomical Society {(MNRAS)}}, year = {2017}, pages = {3101-3114}, volume = {472}, number = {3}, publisher = {Oxford University Press}, tags = {application,ml}, } -
 F. Gieseke, K. L. Polsterer, A. Mahabal, C. Igel, and T. Heskes2017 IEEE Symposium Series on Computational Intelligence, SSCI 2017, Honolulu, HI, USA, November 27 - Dec. 1, 2017 2017
F. Gieseke, K. L. Polsterer, A. Mahabal, C. Igel, and T. Heskes2017 IEEE Symposium Series on Computational Intelligence, SSCI 2017, Honolulu, HI, USA, November 27 - Dec. 1, 2017 2017Selecting an optimal subset of k out of d features for linear regression models given n training instances is often considered intractable for feature spaces with hundreds or thousands of dimensions. We propose an efficient massively-parallel implementation for selecting such optimal feature subsets in a brute-force fashion for small k. By exploiting the enormous compute power provided by modern parallel devices such as graphics processing units, it can deal with thousands of input dimensions even using standard commodity hardware only. We evaluate the practical runtime using artificial datasets and sketch the applicability of our framework in the context of astronomy.
@inproceedings{GiesekePMIH17, author = {Gieseke, Fabian and Polsterer, Kai Lars and Mahabal, Ashish and Igel, Christian and Heskes, Tom}, title = {Massively-parallel best subset selection for ordinary least-squares regression}, booktitle = {2017 {IEEE} Symposium Series on Computational Intelligence, {SSCI} 2017, Honolulu, HI, USA, November 27 - Dec. 1, 2017}, pages = {1--8}, publisher = {{IEEE}}, year = {2017}, doi = {10.1109/SSCI.2017.8285225}, tags = {de,ml}, } -
 T. Pahikkala, A. Airola, F. Gieseke, and O. KramerJournal of Computer Science and Technology (ICDM 2012 Special Issue) 2014
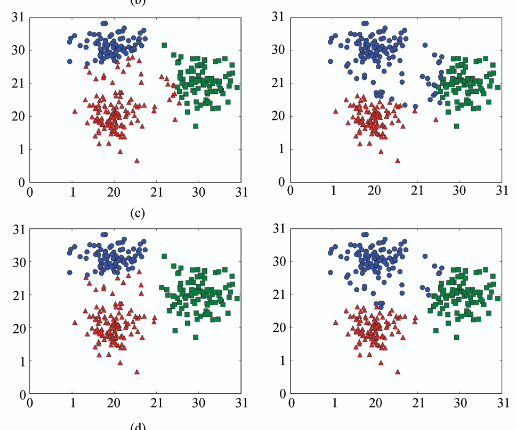
T. Pahikkala, A. Airola, F. Gieseke, and O. KramerJournal of Computer Science and Technology (ICDM 2012 Special Issue) 2014In this work we present the first efficient algorithm for unsupervised training of multi-class regularized least-squares classifiers. The approach is closely related to the unsupervised extension of the support vector machine classifier known as maximum margin clustering, which recently has received considerable attention, though mostly considering the binary classification case. We present a combinatorial search scheme that combines steepest descent strategies with powerful meta-heuristics for avoiding bad local optima. The regularized least-squares based formulation of the problem allows us to use matrix algebraic optimization enabling constant time checks for the intermediate candidate solutions during the search. Our experimental evaluation indicates the potential of the novel method and demonstrates its superior clustering performance over a variety of competing methods on real world datasets. Both time complexity analysis and experimental comparisons show that the method can scale well to practical sized problems.
@article{PahikkalaAGK14, author = {Pahikkala, Tapio and Airola, Antti and Gieseke, Fabian and Kramer, Oliver}, title = {On Unsupervised Training of Multi-Class Regularized Least-Squares Classifiers}, journal = {Journal of Computer Science and Technology (ICDM 2012 Special Issue)}, volume = {29}, number = {1}, pages = {90--104}, year = {2014}, doi = {10.1007/s11390-014-1414-0}, tags = {ml,de}, } -
 F. Gieseke, K. L. Polsterer, C. E. Oancea, and C. Igel22th European Symposium on Artificial Neural Networks, ESANN 2014, Bruges, Belgium, April 23-25, 2014 2014
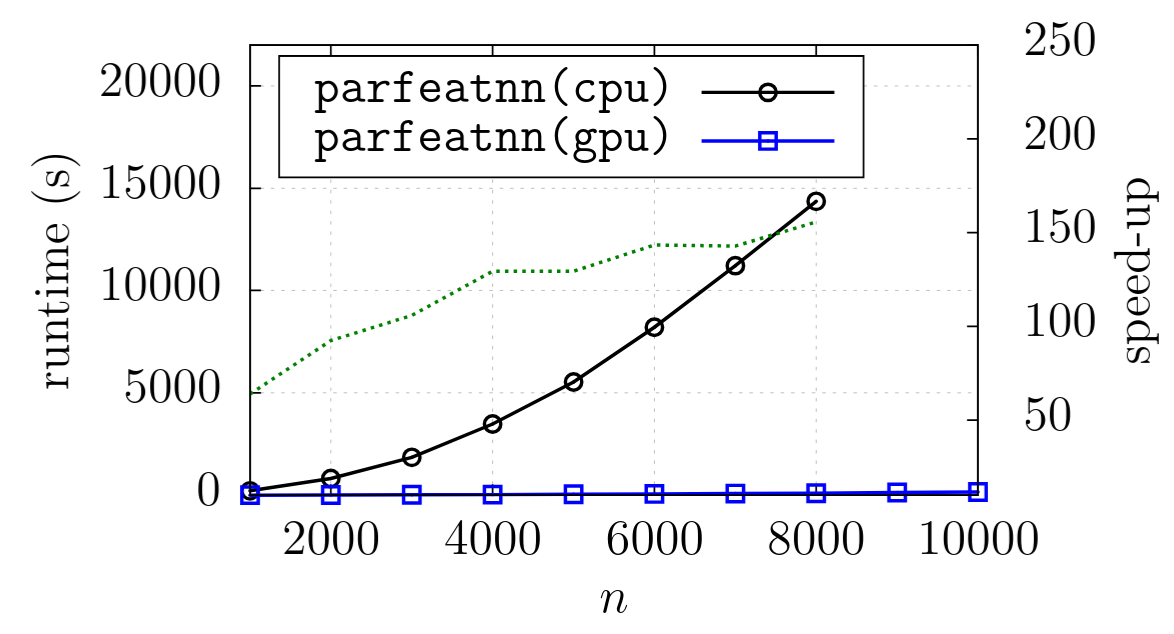
F. Gieseke, K. L. Polsterer, C. E. Oancea, and C. Igel22th European Symposium on Artificial Neural Networks, ESANN 2014, Bruges, Belgium, April 23-25, 2014 2014Nearest neighbor models are among the most basic tools in machine learning, and recent work has demonstrated their effectiveness in the field of astronomy. The performance of these models crucially depends on the underlying metric, and in particular on the selection of a meaningful subset of informative features. The feature selection is task-dependent and usually very time-consuming. In this work, we propose an efficient par- allel implementation of incremental feature selection for nearest neighbor models utilizing nowadays graphics processing units. Our framework pro- vides significant computational speed-ups over its sequential single-core competitor of up to two orders of magnitude. We demonstrate the ap- plicability of the overall scheme on one of the most challenging tasks in astronomy: redshift estimation for distant galaxies.
@inproceedings{GiesekePOI14, author = {Gieseke, Fabian and Polsterer, Kai Lars and Oancea, Cosmin Eugen and Igel, Christian}, title = {Speedy greedy feature selection: Better redshift estimation via massive parallelism}, booktitle = {22th European Symposium on Artificial Neural Networks, {ESANN} 2014, Bruges, Belgium, April 23-25, 2014}, year = {2014}, tags = {ml}, } -
 F. Gieseke, J. Heinermann, C. E. Oancea, and C. IgelICML14 Proceedings of the 31th International Conference on Machine Learning, ICML 2014, Beijing, China, 21-26 June 2014 2014
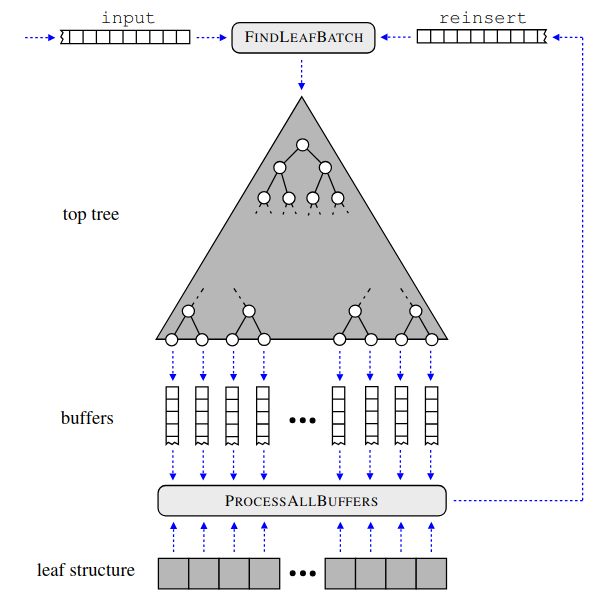
F. Gieseke, J. Heinermann, C. E. Oancea, and C. IgelICML14 Proceedings of the 31th International Conference on Machine Learning, ICML 2014, Beijing, China, 21-26 June 2014 2014We present a new approach for combining k-d trees and graphics processing units for near- est neighbor search. It is well known that a di- rect combination of these tools leads to a non- satisfying performance due to conditional com- putations and suboptimal memory accesses. To alleviate these problems, we propose a variant of the classical k-d tree data structure, called buffer k-d tree, which can be used to reorganize the search. Our experiments show that we can take advantage of both the hierarchical subdivi- sion induced by k-d trees and the huge computa- tional resources provided by today’s many-core devices. We demonstrate the potential of our ap- proach in astronomy, where hundreds of million nearest neighbor queries have to be processed.
@inproceedings{GiesekeHOI14, author = {Gieseke, Fabian and Heinermann, Justin and Oancea, Cosmin E. and Igel, Christian}, title = {Buffer k-d Trees: Processing Massive Nearest Neighbor Queries on GPUs}, booktitle = {Proceedings of the 31th International Conference on Machine Learning, {ICML} 2014, Beijing, China, 21-26 June 2014}, series = {{JMLR} Workshop and Conference Proceedings}, volume = {32}, pages = {172--180}, publisher = {JMLR.org}, year = {2014}, tags = {ml}, } -
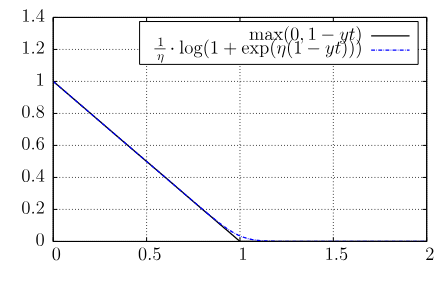 F. GiesekeKI 2013
F. GiesekeKI 2013Support vector machines are among the most popular techniques in machine learning. Given sufficient la- beled data, they often yield excellent results. However, for a variety of real-world tasks, the acquisition of sufficient la- beled data can be very time-consuming; unlabeled data, on the other hand, can often be obtained easily in huge quan- tities. Semi-supervised support vector machines try to take advantage of these additional unlabeled patterns and have been successfully applied in this context. However, they induce a hard combinatorial optimization problem. In this work, we present two optimization strategies that address this task and evaluate the potential of the resulting imple- mentations on real-world data sets, including an example from the field of astronomy.
@article{Gieseke13, author = {Gieseke, Fabian}, title = {From Supervised to Unsupervised Support Vector Machines and Applications in Astronomy}, journal = {{KI}}, volume = {27}, number = {3}, pages = {281--285}, year = {2013}, doi = {10.1007/s13218-013-0248-1}, tags = {ml,de,application}, } -
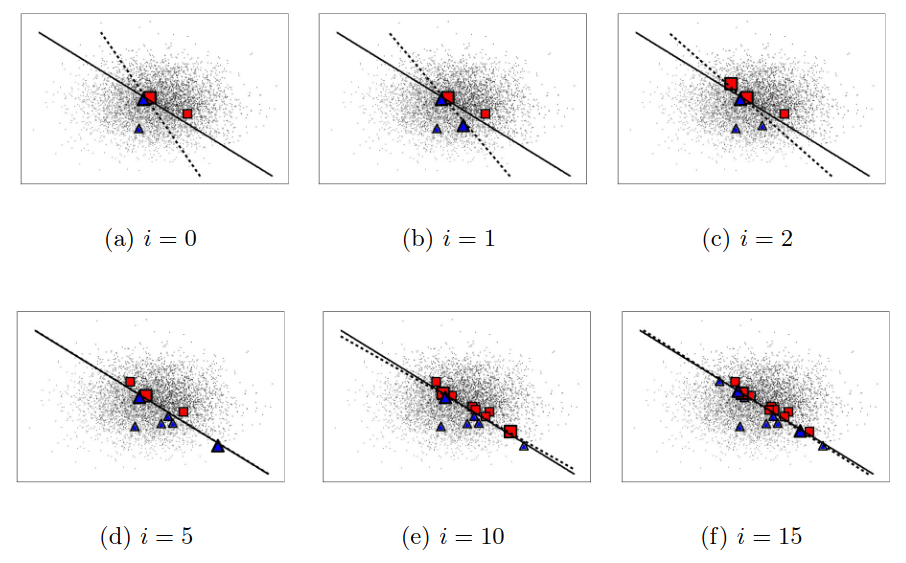
 F. Gieseke, T. Pahikkala, and C. IgelACML13 Asian Conference on Machine Learning, ACML 2013, Canberra, ACT, Australia, November 13-15, 2013 2013
F. Gieseke, T. Pahikkala, and C. IgelACML13 Asian Conference on Machine Learning, ACML 2013, Canberra, ACT, Australia, November 13-15, 2013 2013Maximum margin clustering can be regarded as the direct extension of support vector machines to unsupervised learning scenarios. The goal is to partition unlabeled data into two classes such that a subsequent application of a support vector machine would yield the overall best result (with respect to the optimization problem associated with support vector machines). While being very appealing from a conceptual point of view, the combinatorial nature of the induced optimization problem ren- ders a direct application of this concept difficult. In order to obtain efficient optimization schemes, various surrogates of the original problem definition have been proposed in the literature. In this work, we consider one of these variants, called unsupervised regularized least-squares classifica- tion, which is based on the square loss, and develop polynomial upper runtime bounds for the induced combinatorial optimization task. In particular, we show that for n patterns and kernel ma- trix of fixed rank r (with given eigendecomposition), one can obtain an optimal solution in O(nr) time for r ≤ 2 and in O(nr−1) time for r ≥ 3. The algorithmic framework is based on an inter- esting connection to the field of quadratic zero-one programming and permits the computation of exact solutions for the more general case of non-linear kernel functions in polynomial time.
@inproceedings{GiesekePI13, author = {Gieseke, Fabian and Pahikkala, Tapio and Igel, Christian}, editor = {Ong, Cheng Soon and Ho, Tu Bao}, title = {Polynomial Runtime Bounds for Fixed-Rank Unsupervised Least-Squares Classification}, booktitle = {Asian Conference on Machine Learning, {ACML} 2013, Canberra, ACT, Australia, November 13-15, 2013}, series = {{JMLR} Workshop and Conference Proceedings}, volume = {29}, pages = {62--71}, publisher = {JMLR.org}, year = {2013}, tags = {ml}, } -
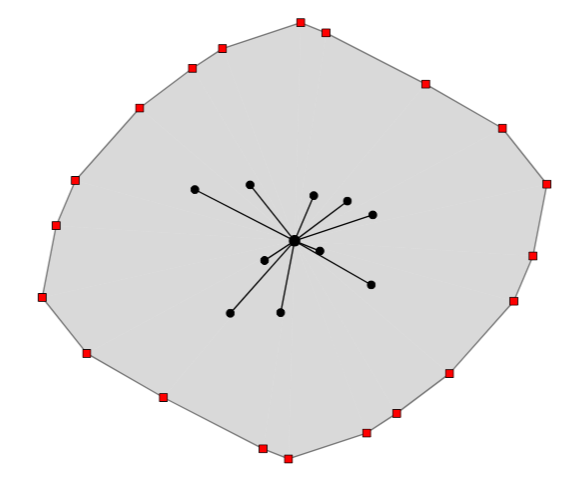
 F. Gieseke, and O. KramerApplications of Evolutionary Computation - 16th European Conference, EvoApplications 2013, Vienna, Austria, April 3-5, 2013. Proceedings 2013
F. Gieseke, and O. KramerApplications of Evolutionary Computation - 16th European Conference, EvoApplications 2013, Vienna, Austria, April 3-5, 2013. Proceedings 2013Constraints can render a numerical optimization problem much more difficult to address. In many real-world optimization appli- cations, however, such constraints are not explicitly given. Instead, one has access to some kind of a “black-box” that represents the (unknown) constraint function. Recently, we proposed a fast linear constraint esti- mator that was based on binary search. This paper extends these results by (a) providing an alternative scheme that resorts to the effective use of support vector machines and by (b) addressing the more general task of non-linear decision boundaries. In particular, we make use of active learning strategies from the field of machine learning to select reasonable training points for the recurrent application of the classifier. We compare both constraint estimation schemes on linear and non-linear constraint functions, and depict opportunities and pitfalls concerning the effective integration of such models into a global optimization process
@inproceedings{GiesekeK13, author = {Gieseke, Fabian and Kramer, Oliver}, editor = {Esparcia{-}Alc{\'{a}}zar, Anna Isabel}, title = {Towards Non-linear Constraint Estimation for Expensive Optimization}, booktitle = {Applications of Evolutionary Computation - 16th European Conference, EvoApplications 2013, Vienna, Austria, April 3-5, 2013. Proceedings}, series = {Lecture Notes in Computer Science}, volume = {7835}, pages = {459--468}, publisher = {Springer}, year = {2013}, tags = {ml}, } -
 F. Gieseke, O. Kramer, A. Airola, and T. PahikkalaEvolutionary Intelligence 2012
F. Gieseke, O. Kramer, A. Airola, and T. PahikkalaEvolutionary Intelligence 2012Binary classification tasks are among the most important ones in the field of machine learning. One prominent approach to address such tasks are support vector machines which aim at finding a hyperplane separating two classes well such that the induced distance between the hyperplane and the patterns is maximized. In general, sufficient labeled data is needed for such classification settings to obtain reasonable models. However, labeled data is often rare in real-world learning scenarios while unlabeled data can be obtained easily. For this reason, the concept of support vector machines has also been extended to semi- and unsupervised settings: in the unsupervised case, one aims at finding a partition of the data into two classes such that a subsequent application of a support vector machine leads to the best overall result. Similarly, given both a labeled and an unlabeled part, semi-supervised support vector machines favor decision hyperplanes that lie in a low density area induced by the unlabeled training patterns, while still considering the labeled part of the data. The associated optimization problems for both the semi- and unsupervised case, however, are of combinatorial nature and, hence, difficult to solve. In this work, we present efficient implementations of simple local search strategies for (variants of) the both cases that are based on matrix update schemes for the intermediate candidate solutions. We evaluate the performances of the resulting approaches on a variety of artificial and real-world data sets. The results indicate that our approaches can successfully incorporate unlabeled data. (The unsupervised case was originally proposed by Gieseke F, Pahikkala et al. (2009). The derivations presented in this work are new and comprehend the old ones (for the unsupervised setting) as a special case.)
@article{GiesekeKAP12, author = {Gieseke, Fabian and Kramer, Oliver and Airola, Antti and Pahikkala, Tapio}, title = {Efficient recurrent local search strategies for semi- and unsupervised regularized least-squares classification}, journal = {Evolutionary Intelligence}, volume = {5}, number = {3}, pages = {189--205}, year = {2012}, doi = {10.1007/s12065-012-0068-5}, tags = {ml} } -
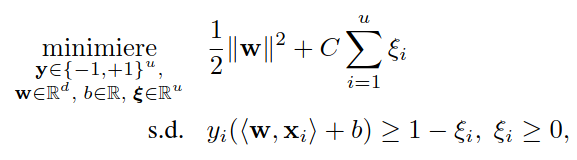 F. GiesekeAusgezeichnete Informatikdissertationen 2012 2012
F. GiesekeAusgezeichnete Informatikdissertationen 2012 2012Ein bekanntes Problem des maschinellen Lernens ist die Klassifikation von Objekten. Entsprechende Modelle basieren dabei meist auf Trainingsdaten, welche aus Mustern mit zugehörigen Labeln bestehen. Die Erstellung eines hinreichend großen Datensatzes kann sich für gewisse Anwendungsfälle jedoch als sehr kosten- oder zeitintensiv erweisen. Eine aktuelle Forschungsrichtung des maschinellen Lernens zielt auf die Verwendung von (zusätzlichen) ungelabelten Mustern ab, welche oft ohne großen Aufwand gewonnen werden können. In diesem Beitrag wird die Erweiterung von sogenannten Support-Vektor-Maschinen auf solche Lernszenarien beschrieben. Im Gegensatz zu Support-Vektor-Maschinen führen diese Varianten jedoch zu kombinatorischen Optimierungsproblemen. Die Entwicklung effizienter Optimierungsstrategien ist daher ein erstrebenswertes Ziel und soll im Rahmen dieses Beitrags diskutiert werden. Weiterhin werden mögliche Anwendungsgebiete der entsprechenden Verfahren erläutert, welche sich unter anderem im Bereich der Astronomie wiederfinden.
@inproceedings{Gieseke12, author = {Gieseke, Fabian}, editor = {H{\"{o}}lldobler, Steffen}, title = {Von {\"{u}}berwachten zu un{\"{u}}berwachten Support-Vektor-Maschinen und Anwendungen in der Astronomie}, booktitle = {Ausgezeichnete Informatikdissertationen 2012}, series = {{LNI}}, volume = {{D-13}}, pages = {111--120}, publisher = {{GI}}, year = {2012}, tags = {ml,de,application}, } -
 T. Pahikkala, A. Airola, F. Gieseke, and O. KramerICDM12 12th IEEE International Conference on Data Mining, ICDM 2012, Brussels, Belgium, December 10-13, 2012 2012
T. Pahikkala, A. Airola, F. Gieseke, and O. KramerICDM12 12th IEEE International Conference on Data Mining, ICDM 2012, Brussels, Belgium, December 10-13, 2012 2012Regularized least-squares classification is one of the most promising alternatives to standard support vector machines, with the desirable property of closed-form solutions that can be obtained analytically, and efficiently. While the supervised, and mostly binary case has received tremendous attention in recent years, unsupervised multi-class settings have not yet been considered. In this work we present an efficient implementation for the unsupervised extension of the multi-class regularized least-squares classification framework, which is, to the best of the authors’ knowledge, the first one in the literature addressing this task. The resulting kernel-based framework efficiently combines steepest descent strategies with powerful meta-heuristics for avoiding local minima. The computational efficiency of the overall approach is ensured through the application of matrix algebra shortcuts that render efficient updates of the intermediate can- didate solutions possible. Our experimental evaluation indicates the potential of the novel method, and demonstrates its superior clustering performance over a variety of competing methods on real-world data sets.
@inproceedings{PahikkalaAGK12, author = {Pahikkala, Tapio and Airola, Antti and Gieseke, Fabian and Kramer, Oliver}, editor = {Zaki, Mohammed Javeed and Siebes, Arno and Yu, Jeffrey Xu and Goethals, Bart and Webb, Geoffrey I. and Wu, Xindong}, title = {Unsupervised Multi-class Regularized Least-Squares Classification}, booktitle = {12th {IEEE} International Conference on Data Mining, {ICDM} 2012, Brussels, Belgium, December 10-13, 2012}, pages = {585--594}, publisher = {{IEEE} Computer Society}, year = {2012}, doi = {10.1109/ICDM.2012.71}, tags = {ml}, } -
 F. Gieseke, A. Airola, T. Pahikkala, and O. KramerICPRAM 2012 - Proceedings of the 1st International Conference on Pattern Recognition Applications and Methods, Volume 1, Vilamoura, Algarve, Portugal, 6-8 February, 2012 2012
F. Gieseke, A. Airola, T. Pahikkala, and O. KramerICPRAM 2012 - Proceedings of the 1st International Conference on Pattern Recognition Applications and Methods, Volume 1, Vilamoura, Algarve, Portugal, 6-8 February, 2012 2012In real-world scenarios, labeled data is often rare while unlabeled data can be obtained in huge quantities. A current research direction in machine learning is the concept of semi-supervised support vector machines. This type of binary classification approach aims at taking the additional information provided by unlabeled patterns into account to reveal more information about the structure of the data and, hence, to yield models with a better classification performance. However, generating these semi-supervised models requires solving difficult optimization tasks. In this work, we present a simple but effective approach to address the induced optimization task, which is based on a special instance of the quasi-Newton family of optimization schemes. The resulting framework can be implemented easily using black box optimization engines and yields excel- lent classification and runtime results on both artificial and real-world data sets that are superior (or at least competitive) to the ones obtained by competing state-of-the-art methods.
@inproceedings{GiesekeAPK12, author = {Gieseke, Fabian and Airola, Antti and Pahikkala, Tapio and Kramer, Oliver}, editor = {Carmona, Pedro Latorre and S{\'{a}}nchez, J. Salvador and Fred, Ana L. N.}, title = {Sparse Quasi-Newton Optimization for Semi-supervised Support Vector Machines}, booktitle = {{ICPRAM} 2012 - Proceedings of the 1st International Conference on Pattern Recognition Applications and Methods, Volume 1, Vilamoura, Algarve, Portugal, 6-8 February, 2012}, pages = {45--54}, publisher = {SciTePress}, year = {2012}, tags = {ml}, } -
 F. Giesekethesis Carl von Ossietzky University of Oldenburg 2011
F. Giesekethesis Carl von Ossietzky University of Oldenburg 2011A common task in the field of machine learning is the classification of objects. The basis for such a task is usually a training set consisting of patterns and associated class labels. A typical example is, for instance, the automatic classification of stars and galaxies in the field of astronomy. Here, the training set could consist of images and associated labels, which indicate whether a particular image shows a star or a galaxy. For such a learning scenario, one aims at generating models that can automatically classify new, unseen images. In the field of machine learning, various classification schemes have been proposed. One of the most popular ones is the concept of support vector machines, which often yields excellent classification results given sufficient labeled data. However, for a variety of real-world tasks, the acquisition of sufficient labeled data can be quite time-consuming. In contrast to labeled training data, unlabeled one can often be obtained easily in huge quantities. Semi- and unsupervised techniques aim at taking these unlabeled patterns into account to generate appropriate models. In the literature, various ways of extending support vector machines to these scenarios have been proposed. One of these ways leads to combinatorial optimization tasks that are difficult to address. In this thesis, several optimization strategies will be developed for these tasks that (1) aim at solving them exactly or (2) aim at obtaining (possibly suboptimal) candidate solutions in an efficient kind of way. More specifically, we will derive a polynomial-time approach that can compute exact solutions for special cases of both tasks. This approach is among the first ones that provide upper runtime bounds for the tasks at hand and, thus, yield theoretical insights into their computational complexity. In addition to this exact scheme, two heuristics tackling both problems will be provided. The first one is based on least-squares variants of the original tasks whereas the second one relies on differentiable surrogates for the corresponding objective functions. While direct implementations of both heuristics are still computationally expensive, we will show how to make use of matrix operations to speed up their execution. This will result in two optimization schemes that exhibit an excellent classification and runtime performance. Despite these theoretical derivations, we will also depict possible application domains of machine learning methods in astronomy. Here, the massive amount of data given for today’s and future projects renders a manual analysis impossible and necessitates the use of sophisticated techniques. In this context, we will derive an efficient way to preprocess spectroscopic data, which is based on an adaptation of support vector machines, and the benefits of semi-supervised learning schemes for appropriate learning tasks will be sketched. As a further contribution to this field, we will propose the use of so-called resilient algorithms for the automatic data analysis taking place aboard today’s spacecrafts and will demonstrate their benefits in the context of clustering hyperspectral image data.
@phdthesis{Gieseke2011, author = {Gieseke, Fabian}, title = {From supervised to unsupervised support vector machines and applications in astronomy}, school = {Carl von Ossietzky University of Oldenburg}, year = {2011}, tags = {ml,de,application} } -
 F. Gieseke, O. Kramer, A. Airola, and T. PahikkalaKI 2011: Advances in Artificial Intelligence, 34th Annual German Conference on AI, Berlin, Germany, October 4-7,2011. Proceedings 2011
F. Gieseke, O. Kramer, A. Airola, and T. PahikkalaKI 2011: Advances in Artificial Intelligence, 34th Annual German Conference on AI, Berlin, Germany, October 4-7,2011. Proceedings 2011@inproceedings{GiesekeKAP11, author = {Gieseke, Fabian and Kramer, Oliver and Airola, Antti and Pahikkala, Tapio}, editor = {Bach, Joscha and Edelkamp, Stefan}, title = {Speedy Local Search for Semi-Supervised Regularized Least-Squares}, booktitle = {{KI} 2011: Advances in Artificial Intelligence, 34th Annual German Conference on AI, Berlin, Germany, October 4-7,2011. Proceedings}, series = {Lecture Notes in Computer Science}, volume = {7006}, pages = {87--98}, publisher = {Springer}, year = {2011}, doi = {10.1007/978-3-642-24455-1\_8}, tags = {ml} } -
 F. Gieseke, T. Pahikkala, and O. KramerICML09 Proceedings of the 26th Annual International Conference on Machine Learning, ICML 2009, Montreal, Quebec, Canada, June 14-18, 2009 2009
F. Gieseke, T. Pahikkala, and O. KramerICML09 Proceedings of the 26th Annual International Conference on Machine Learning, ICML 2009, Montreal, Quebec, Canada, June 14-18, 2009 2009The maximum margin clustering approach is a recently proposed extension of the concept of support vector machines to the clustering problem. Briefly stated, it aims at finding an optimal partition of the data into two classes such that the margin induced by a subsequent application of a support vector machine is maximal. We propose a method based on stochastic search to address this hard optimization problem. While a direct implementation would be infeasible for large data sets, we present an efficient computa- tional shortcut for assessing the “quality” of intermediate solutions. Experimental results show that our approach outperforms existing methods in terms of clustering accuracy.
@inproceedings{GiesekePK09, author = {Gieseke, Fabian and Pahikkala, Tapio and Kramer, Oliver}, editor = {Danyluk, Andrea Pohoreckyj and Bottou, L{\'{e}}on and Littman, Michael L.}, title = {Fast evolutionary maximum margin clustering}, booktitle = {Proceedings of the 26th Annual International Conference on Machine Learning, {ICML} 2009, Montreal, Quebec, Canada, June 14-18, 2009}, series = {{ACM} International Conference Proceeding Series}, volume = {382}, pages = {361--368}, publisher = {{ACM}}, year = {2009}, doi = {10.1145/1553374.1553421}, tags = {ml}, }








































