Publications tagged "hpc"
-
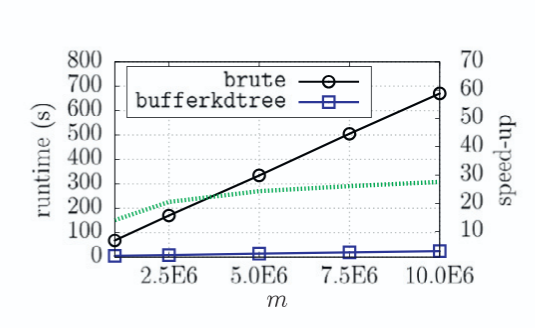 F. Gieseke, C. E. Oancea, and C. IgelKnowledge Based Systems 2017
F. Gieseke, C. E. Oancea, and C. IgelKnowledge Based Systems 2017The bufferkdtree package is an open-source software that provides an efficient implementation for processing huge amounts of nearest neighbor queries in Euclidean spaces of moderate dimensionality. Its underlying implementation resorts to a variant of the classical k-d tree data structure, called buffer k-d tree, which can be used to efficiently perform bulk nearest neighbor searches on modern many-core devices. The package, which is based on Python, C, and OpenCL, is made publicly available online at https://github.com/gieseke/bufferkdtree under the GPLv2 license.
@article{GiesekeOI17, author = {Gieseke, Fabian and Oancea, Cosmin E. and Igel, Christian}, title = {bufferkdtree: {A} Python library for massive nearest neighbor queries on multi-many-core devices}, journal = {Knowledge Based Systems}, volume = {120}, pages = {1--3}, year = {2017}, doi = {10.1016/j.knosys.2017.01.002}, tags = {de,hpc}, } -
 K. L. Polsterer, F. Gieseke, C. Igel, B. Doser, and N. Gianniotis24th European Symposium on Artificial Neural Networks, ESANN 2016, Bruges, Belgium, April 27-29, 2016 2016
K. L. Polsterer, F. Gieseke, C. Igel, B. Doser, and N. Gianniotis24th European Symposium on Artificial Neural Networks, ESANN 2016, Bruges, Belgium, April 27-29, 2016 2016@inproceedings{PolstererGIDG16, author = {Polsterer, Kai Lars and Gieseke, Fabian and Igel, Christian and Doser, Bernd and Gianniotis, Nikolaos}, title = {Parallelized rotation and flipping INvariant Kohonen maps {(PINK)} on GPUs}, booktitle = {24th European Symposium on Artificial Neural Networks, {ESANN} 2016, Bruges, Belgium, April 27-29, 2016}, year = {2016}, tags = {de,application,hpc}, } -
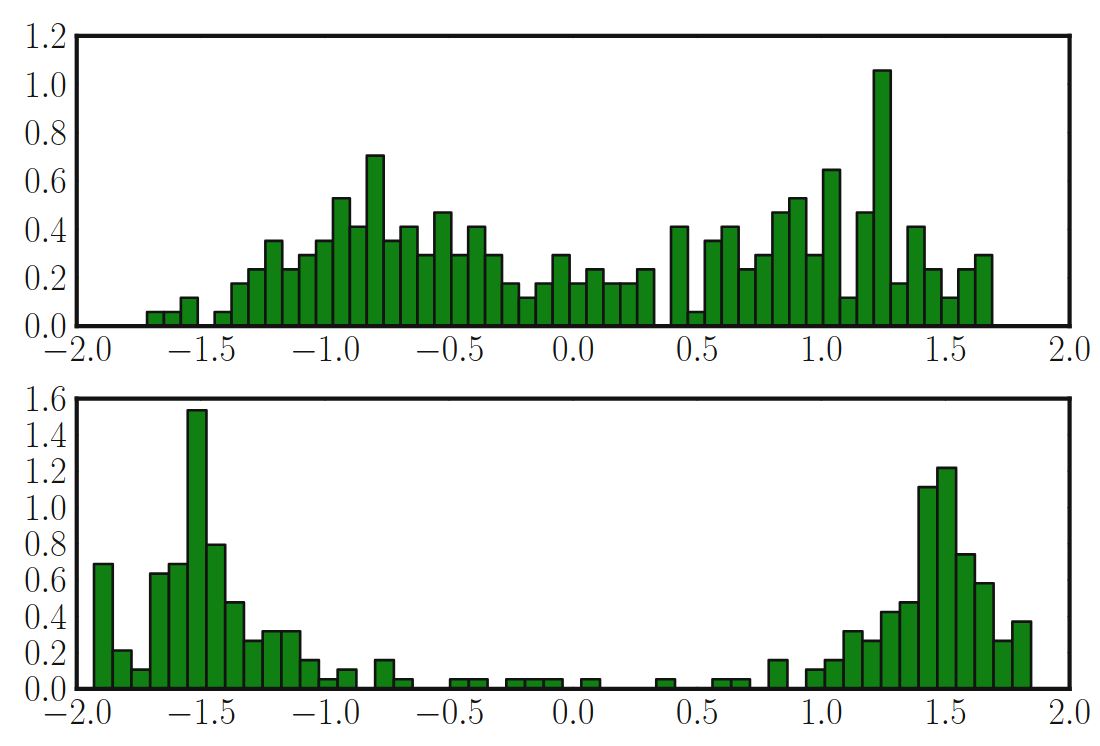 F. GiesekeMachine Learning, Optimization, and Big Data - First International Workshop, MOD 2015, Taormina, Sicily, Italy, July 21-23, 2015, Revised Selected Papers 2015
F. GiesekeMachine Learning, Optimization, and Big Data - First International Workshop, MOD 2015, Taormina, Sicily, Italy, July 21-23, 2015, Revised Selected Papers 2015The concept of semi-supervised support vector machines extends classical support vector machines to learning scenarios, where both labeled and unlabeled patterns are given. In recent years, such semi-supervised extensions have gained considerable attention due to their huge potential for real-world applications with only small amounts of labeled data. While being appealing from a practical point of view, semi-supervised support vector machines lead to a combinatorial optimization problem that is difficult to address. Many optimization approaches have been proposed that aim at tackling this task. However, the computational requirements can still be very high, especially in case large data sets are considered and many model parameters need to be tuned. A recent trend in the field of big data analytics is to make use of graphics processing units to speed up computationally intensive tasks. In this work, such a massively-parallel implementation is developed for semi-supervised support vector machines. The experimental evaluation, conducted on commodity hardware, shows that valuable speed-ups of up to two orders of magnitude can be achieved over a standard single-core CPU execution.
@inproceedings{Gieseke15, author = {Gieseke, Fabian}, editor = {Pardalos, Panos M. and Pavone, Mario and Farinella, Giovanni Maria and Cutello, Vincenzo}, title = {An Efficient Many-Core Implementation for Semi-Supervised Support Vector Machines}, booktitle = {Machine Learning, Optimization, and Big Data - First International Workshop, {MOD} 2015, Taormina, Sicily, Italy, July 21-23, 2015, Revised Selected Papers}, series = {Lecture Notes in Computer Science}, volume = {9432}, pages = {145--157}, publisher = {Springer}, year = {2015}, doi = {10.1007/978-3-319-27926-8\_13}, tags = {hpc}, } -
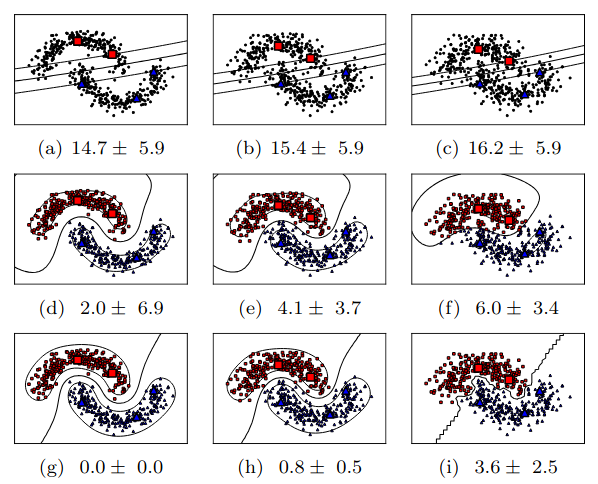 F. Gieseke, A. Airola, T. Pahikkala, and O. KramerNeurocomputing 2014
F. Gieseke, A. Airola, T. Pahikkala, and O. KramerNeurocomputing 2014One of the main learning tasks in machine learning is the one of classifying data items. The basis for such a task is usually a training set consisting of labeled patterns. In real-world settings, however, such labeled data are usually scarce, and the corresponding models might yield unsatisfying results. Unlabeled data, on the other hand, can often be obtained in huge quantities without much additional effort. A prominent research direction in the field of machine learning is semi-supervised support vector machines. This type of binary classification approach aims at taking the additional information provided by the unlabeled patterns into account to reveal more information about the structure of the data at hand. In some cases, this can yield significantly better classification results compared to a straightforward application of supervised models. One drawback, however, is the fact that generating such models requires solving difficult non-convex optimization tasks. In this work, we present a simple but effective gradient-based optimization framework to address the induced problems. The resulting method can be implemented easily using black-box optimization engines and yields excellent classification and runtime results on both sparse and non-sparse data sets.
@article{GiesekeAPK14, author = {Gieseke, Fabian and Airola, Antti and Pahikkala, Tapio and Kramer, Oliver}, title = {Fast and simple gradient-based optimization for semi-supervised support vector machines}, journal = {Neurocomputing}, volume = {123}, pages = {23--32}, year = {2014}, doi = {10.1016/j.neucom.2012.12.056}, tags = {hpc} } -
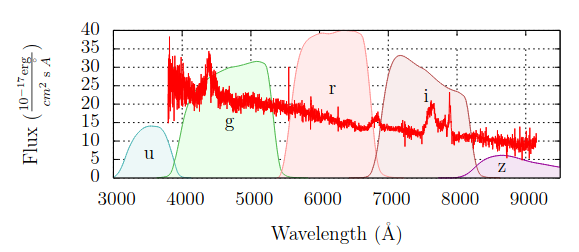 J. Heinermann, O. Kramer, K. L. Polsterer, and F. GiesekeKI 2013: Advances in Artificial Intelligence - 36th Annual German Conference on AI, Koblenz, Germany, September 16-20, 2013. Proceedings 2013
J. Heinermann, O. Kramer, K. L. Polsterer, and F. GiesekeKI 2013: Advances in Artificial Intelligence - 36th Annual German Conference on AI, Koblenz, Germany, September 16-20, 2013. Proceedings 2013Nowadays astronomical catalogs contain patterns of hundreds of millions of objects with data volumes in the terabyte range. Upcoming projects will gather such patterns for several billions of objects with peta- and exabytes of data. From a machine learning point of view, these settings often yield unsupervised, semi-supervised, or fully supervised tasks, with large training and huge test sets. Recent studies have demonstrated the effectiveness of prototype-based learning schemes such as simple nearest neighbor models. However, although being among the most computationally efficient methods for such settings (if implemented via spatial data structures), applying these models on all remaining patterns in a given catalog can easily take hours or even days. In this work, we investigate the practical effectiveness of GPU-based approaches to accelerate such nearest neighbor queries in this context. Our experiments indicate that carefully tuned implementations of spatial search structures for such multi-core devices can significantly reduce the practical runtime. This renders the resulting frameworks an important algorithmic tool for current and upcoming data analyses in astronomy.
@inproceedings{HeinermannKPG13, author = {Heinermann, Justin and Kramer, Oliver and Polsterer, Kai Lars and Gieseke, Fabian}, editor = {Timm, Ingo J. and Thimm, Matthias}, title = {On GPU-Based Nearest Neighbor Queries for Large-Scale Photometric Catalogs in Astronomy}, booktitle = {{KI} 2013: Advances in Artificial Intelligence - 36th Annual German Conference on AI, Koblenz, Germany, September 16-20, 2013. Proceedings}, series = {Lecture Notes in Computer Science}, volume = {8077}, pages = {86--97}, publisher = {Springer}, year = {2013}, doi = {10.1007/978-3-642-40942-4\_8}, tags = {hpc}, }




