Publications tagged "de"
-
 N. Herrmann, J. Stenkamp, B. Karic, S. Oehmcke, and F. GiesekeICLR26 The Fourteenth International Conference on Learning Representations (ICLR) 2026
N. Herrmann, J. Stenkamp, B. Karic, S. Oehmcke, and F. GiesekeICLR26 The Fourteenth International Conference on Learning Representations (ICLR) 2026Deploying machine learning models on compute-constrained devices has become a key building block of modern IoT applications. In this work, we present a compression scheme for boosted decision trees, addressing the growing need for lightweight machine learning models. Specifically, we provide techniques for training compact boosted decision tree ensembles that exhibit a reduced memory footprint by rewarding, among other things, the reuse of features and thresholds during training. Our experimental evaluation shows that models achieved the same performance with a compression ratio of 4–16x compared to LightGBM models using an adapted training process and an alternative memory layout. Once deployed, the corresponding IoT devices can operate independently of constant communication or external energy supply, and, thus, autonomously, requiring only minimal computing power and energy. This capability opens the door to a wide range of IoT applications, including remote monitoring, edge analytics, and real-time decision making in isolated or power-limited environments.
@inproceedings{treesonadiet, title = {Boosted Trees on a Diet: Compact Models for Resource-Constrained Devices}, author = {Herrmann, Nina and Stenkamp, Jan and Karic, Benjamin and Oehmcke, Stefan and Gieseke, Fabian}, booktitle = {The Fourteenth International Conference on Learning Representations (ICLR)}, year = {2026}, tags = {ml,de,energy,rs}, projects = {tinyaiot}, url = {https://openreview.net/forum?id=batDcksZsh} } -
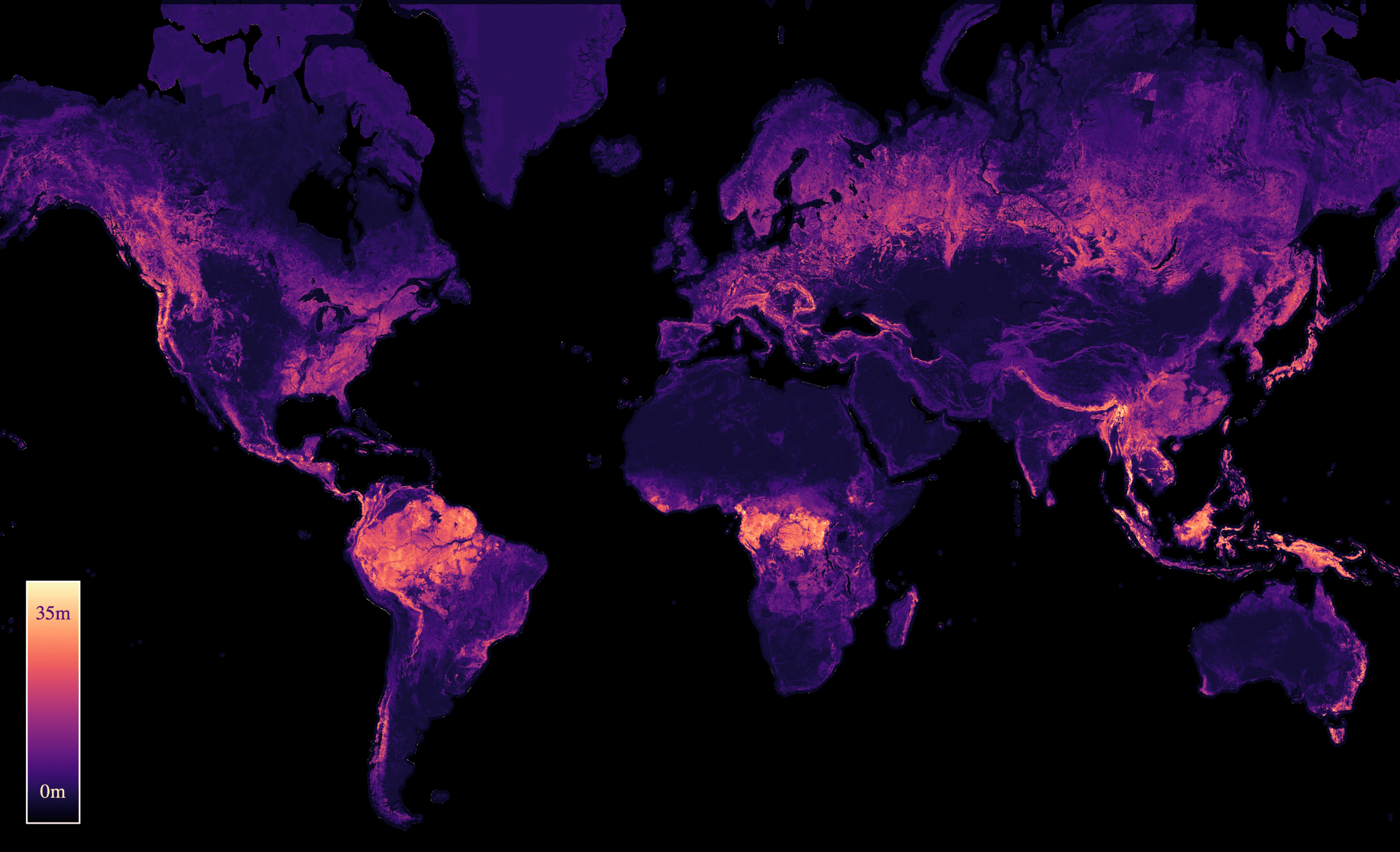 J. Pauls, M. Zimmer, U. M. Kelly, M. Schwartz, S. Saatchi, P. Ciais, S. Pokutta, M. Brandt, and F. GiesekeICML24 41st International Conference on Machine Learning (ICML) 2024
J. Pauls, M. Zimmer, U. M. Kelly, M. Schwartz, S. Saatchi, P. Ciais, S. Pokutta, M. Brandt, and F. GiesekeICML24 41st International Conference on Machine Learning (ICML) 2024We propose a framework for global-scale canopy height estimation based on satellite data. Our model leverages advanced data preprocessing techniques, resorts to a novel loss function designed to counter geolocation inaccuracies inherent in the ground-truth height measurements, and employs data from the Shuttle Radar Topography Mission to effectively filter out erroneous labels in mountainous regions, enhancing the reliability of our predictions in those areas. A comparison between predictions and ground-truth labels yields an MAE / RMSE of 2.43 / 4.73 (meters) overall and 4.45 / 6.72 (meters) for trees taller than five meters, which depicts a substantial improvement compared to existing global-scale maps. The resulting height map as well as the underlying framework will facilitate and enhance ecological analyses at a global scale, including, but not limited to, large-scale forest and biomass monitoring.
@inproceedings{pauls2024estimating, title = {Estimating Canopy Height at Scale}, author = {Pauls, Jan and Zimmer, Max and Kelly, Una M. and Schwartz, Martin and Saatchi, Sassan and Ciais, Philippe and Pokutta, Sebastian and Brandt, Martin and Gieseke, Fabian}, booktitle = {41st International Conference on Machine Learning (ICML)}, year = {2024}, custom = {Earth Engine|https://worldwidemap.projects.earthengine.app/view/canopy-height-2020}, tags = {ml,de,application}, projects = {ai4forest} } -
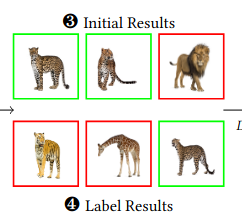 C. Lülf, D. M. Lima Martins, S. M. A. Vaz, Y. Zhou, and F. GiesekeSIGIR24 Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (Demo Track) 2024
C. Lülf, D. M. Lima Martins, S. M. A. Vaz, Y. Zhou, and F. GiesekeSIGIR24 Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (Demo Track) 2024The advent of text-image models, most notably CLIP, has signifi- cantly transformed the landscape of information retrieval. These models enable the fusion of various modalities, such as text and images. One significant outcome of CLIP is its capability to allow users to search for images using text as a query, as well as vice versa. This is achieved via a joint embedding of images and text data that can, for instance, be used to search for similar items. De- spite efficient query processing techniques such as approximate nearest neighbor search, the results may lack precision and com- pleteness. We introduce CLIP-Branches, a novel text-image search engine built upon the CLIP architecture. Our approach enhances traditional text-image search engines by incorporating an interac- tive fine-tuning phase, which allows the user to further concretize the search query by iteratively defining positive and negative exam- ples. Our framework involves training a classification model given the additional user feedback and essentially outputs all positively classified instances of the entire data catalog. By building upon re- cent techniques, this inference phase, however, is not implemented by scanning the entire data catalog, but by employing efficient index structures pre-built for the data. Our results show that the fine-tuned results can improve the initial search outputs in terms of relevance and accuracy while maintaining swift response times
@inproceedings{LuelfLMVZG2024CLIPBranches, author = {Lülf, Christian and {Lima Martins}, Denis Mayr and Vaz, Salles Marcos Antonio and Zhou, Yongluan and Gieseke, Fabian}, title = {CLIP-Branches: Interactive Fine-Tuning for Text-Image Retrieval}, booktitle = {Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval (Demo Track)}, year = {2024}, address = {Washington, D.C.}, tags = {ml,de}, } -
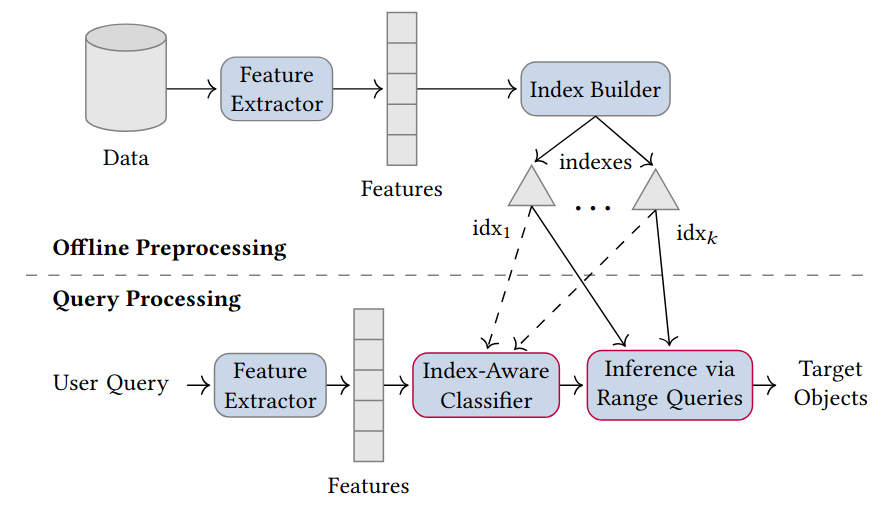 C. Lülf, D. M. Lima Martins, S. M. A. Vaz, Y. Zhou, and F. GiesekeVLDB23 Proceedings of the VLDB Endowment 2023
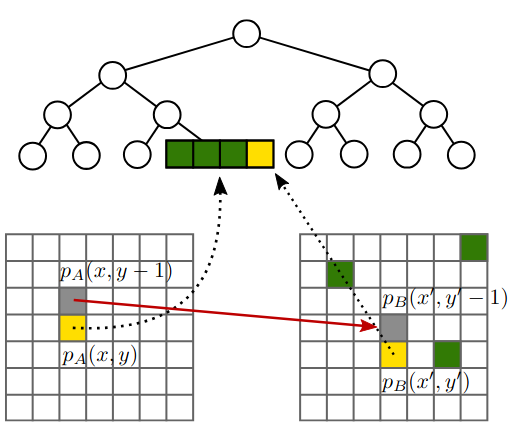
C. Lülf, D. M. Lima Martins, S. M. A. Vaz, Y. Zhou, and F. GiesekeVLDB23 Proceedings of the VLDB Endowment 2023The vast amounts of data collected in various domains pose great challenges to modern data exploration and analysis. To find “inter- esting” objects in large databases, users typically define a query using positive and negative example objects and train a classifi- cation model to identify the objects of interest in the entire data catalog. However, this approach requires a scan of all the data to apply the classification model to each instance in the data catalog, making this method prohibitively expensive to be employed in large-scale databases serving many users and queries interactively. In this work, we propose a novel framework for such search-by- classification scenarios that allows users to interactively search for target objects by specifying queries through a small set of positive and negative examples. Unlike previous approaches, our frame- work can rapidly answer such queries at low cost without scanning the entire database. Our framework is based on an index-aware construction scheme for decision trees and random forests that transforms the inference phase of these classification models into a set of range queries, which in turn can be efficiently executed by leveraging multidimensional indexing structures. Our experiments show that queries over large data catalogs with hundreds of millions of objects can be processed in a few seconds using a single server, compared to hours needed by classical scanning-based approaches.
@inproceedings{LuelfLMVZG2023FastSearchByClassification, author = {Lülf, Christian and {Lima Martins}, Denis Mayr and Vaz, Salles Marcos Antonio and Zhou, Yongluan and Gieseke, Fabian}, title = {Fast Search-By-Classification for Large-Scale Databases Using Index-Aware Decision Trees and Random Forests}, booktitle = {Proceedings of the VLDB Endowment}, pages = {2845--2857}, volume = {16}, editor = {VLDB, Endowment}, year = {2023}, publisher = {ACM Press}, address = {Vancouver}, issn = {2150-8097}, doi = {10.14778/3611479.3611492}, tags = {ml,de} } -
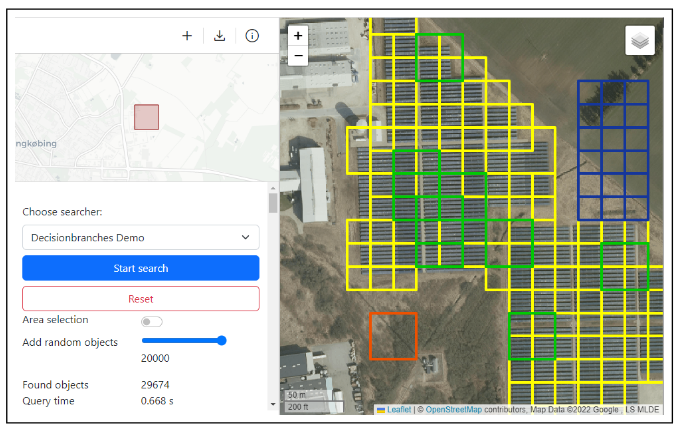 RapidEarth: A Search Engine for Large-Scale Geospatial Imagery Best Demo AwardC. Lülf, D. M. Lima Martins, S. M. A. Vaz, Y. Zhou, and F. GiesekeSIGSPATIAL23 Proceedings of the 31st International Conference on Advances in Geographic Information Systems, SIGSPATIAL, Demo Paper, 2023 (Best Demo Award) 2023
RapidEarth: A Search Engine for Large-Scale Geospatial Imagery Best Demo AwardC. Lülf, D. M. Lima Martins, S. M. A. Vaz, Y. Zhou, and F. GiesekeSIGSPATIAL23 Proceedings of the 31st International Conference on Advances in Geographic Information Systems, SIGSPATIAL, Demo Paper, 2023 (Best Demo Award) 2023Data exploration and analysis in various domains often necessitate the search for specific objects in massive databases. A common search strategy, often known as search-by-classification, resorts to training machine learning models on small sets of positive and negative samples and to performing inference on the entire database to discover additional objects of interest. While such an approach often yields very good results in terms of classification performance, the entire database usually needs to be scanned, a process that can easily take several hours even for medium-sized data catalogs. In this work, we present RapidEarth, a geospatial search-by-classification engine that allows analysts to rapidly search for interesting objects in very large data collections of satellite imagery in a matter of seconds, without the need to scan the entire data catalog. RapidEarth embodies a co-design of multidimensional indexing structures and decision branches, a recently proposed variant of classical decision trees. These decision branches allow RapidEarth to transform the inference phase into a set of range queries, which can be efficiently processed by leveraging the aforementioned multidimensional indexing structures. The main contribution of this work is a geospatial search engine that implements these technical findings.
-
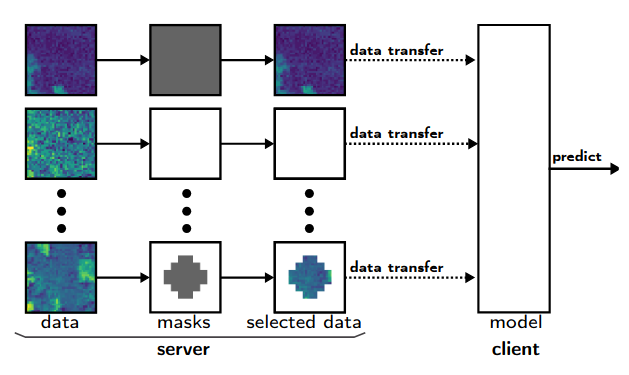 S. Oehmcke, and F. GiesekeSDM22 Proceedings of the 2022 SIAM International Conference on Data Mining (SDM) 2022
S. Oehmcke, and F. GiesekeSDM22 Proceedings of the 2022 SIAM International Conference on Data Mining (SDM) 2022Data are often accommodated on centralized storage servers. This is the case, for instance, in remote sensing and astronomy, where projects produce several petabytes of data every year. While machine learning models are often trained on relatively small subsets of the data, the inference phase typically requires transferring significant amounts of data between the servers and the clients. In many cases, the bandwidth available per user is limited, which then renders the data transfer to be one of the major bottlenecks. In this work, we propose a framework that automatically selects the relevant parts of the input data for a given neural network. The model as well as the associated selection masks are trained simultaneously such that a good model performance is achieved while only a minimal amount of data is selected. During the inference phase, only those parts of the data have to be transferred between the server and the client. We propose both instance-independent and instance-dependent selection masks. The former ones are the same for all instances to be transferred, whereas the latter ones allow for variable transfer sizes per instance. Our experiments show that it is often possible to significantly reduce the amount of data needed to be transferred without affecting the model quality much.
@inproceedings{OehmckeG2022InputSelection, author = {Oehmcke, Stefan and Gieseke, Fabian}, title = {Input Selection for Bandwidth-Limited Neural Network Inference}, booktitle = {Proceedings of the 2022 SIAM International Conference on Data Mining (SDM)}, pages = {280--288}, editor = {Banerjee, Arindam and Zhou, Zhi-Hua and Papalexakis, Evangelos E. and Riondato, Matteo}, year = {2022}, publisher = {SIAM Publications}, address = {USA}, doi = {10.1137/1.9781611977172.32}, tags = {ml,de}, } -
 Dataset Sensitive Autotuning of Multi-versioned Code Based on Monotonic Properties — Autotuning in Futhark Best Paper AwardP. Munksgaard, S. L. Breddam, T. Henriksen, F. Gieseke, and C. E. OanceaTFP21 Proceedings of the 22nd International Symposium on Trends in Functional Programming (TFP) (Best Paper Award) 2021
Dataset Sensitive Autotuning of Multi-versioned Code Based on Monotonic Properties — Autotuning in Futhark Best Paper AwardP. Munksgaard, S. L. Breddam, T. Henriksen, F. Gieseke, and C. E. OanceaTFP21 Proceedings of the 22nd International Symposium on Trends in Functional Programming (TFP) (Best Paper Award) 2021Functional languages allow rewrite-rule systems that aggressively generate a multitude of semantically-equivalent but differently-optimized code versions. In the context of GPGPU execution, this paper addresses the important question of how to compose these code versions into a single program that (near-)optimally discriminates them across different datasets. Rather than aiming at a general autotuning framework reliant on stochastic search, we argue that in some cases, a more effective solution can be obtained by customizing the tuning strategy for the compiler transformation producing the code versions. We present a simple and highly-composable strategy which requires that the (dynamic) program property used to discriminate between code versions conforms with a certain monotonicity assumption. Assuming the monotonicity assumption holds, our strategy guarantees that if an optimal solution exists it will be found. If an optimal solution doesn’t exist, our strategy produces human tractable and deterministic results that provide insights into what went wrong and how it can be fixed. We apply our tuning strategy to the incremental-flattening transformation supported by the publicly-available Futhark compiler and compare with a previous black-box tuning solution that uses the popular OpenTuner library. We demonstrate the feasibility of our solution on a set of standard datasets of real-world applications and public benchmark suites, such as Rodinia and FinPar. We show that our approach shortens the tuning time by a factor of 6× on average, and more importantly, in five out of eleven cases, it produces programs that are (as high as 10×) faster than the ones produced by the OpenTuner-based technique.
@inproceedings{MunksgaardBHGO2021DatasetSensitive, author = {Munksgaard, Philip and Breddam, Svend Lund and Henriksen, Troels and Gieseke, Fabian and Oancea, Cosmin Eugen}, title = {Dataset Sensitive Autotuning of Multi-versioned Code Based on Monotonic Properties --- Autotuning in Futhark}, booktitle = {Proceedings of the 22nd International Symposium on Trends in Functional Programming (TFP)}, pages = {3--23}, series = {Lecture Notes in Computer Science}, volume = {12834}, year = {2021}, publisher = {Springer}, address = {Virtual Event}, doi = {10.1007/978-3-030-83978-9}, tags = {de}, } -
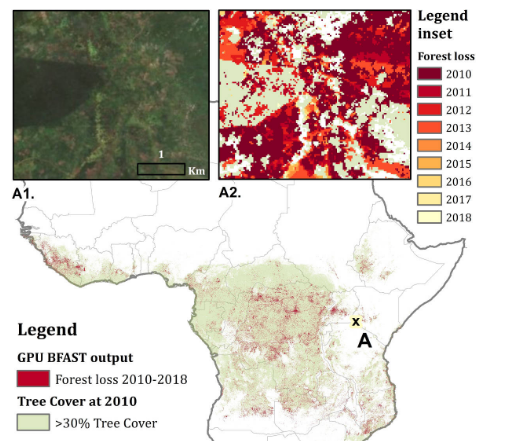 F. Gieseke, S. Rosca, T. Henriksen, J. Verbesselt, and C. E. OanceaICDE20 Proceedings of the 36th IEEE International Conference on Data Engineering (ICDE) 2020
F. Gieseke, S. Rosca, T. Henriksen, J. Verbesselt, and C. E. OanceaICDE20 Proceedings of the 36th IEEE International Conference on Data Engineering (ICDE) 2020Large amounts of satellite data are now becoming available, which, in combination with appropriate change detection methods, offer the opportunity to derive accurate information on timing and location of disturbances such as deforestation events across the earth surface. Typical scenarios require the analysis of billions of image patches/pixels. While various change detection techniques have been proposed in the literature, the associated implementations usually do not scale well, which renders the corresponding analyses computationally very expensive or even impossible. In this work, we propose a novel massively-parallel implementation for a state-of-the-art change detection method and demonstrate its potential in the context of monitoring deforestation. The novel implementation can handle large scenarios in a few hours or days using cheap commodity hardware, compared to weeks or even years using the existing publicly available code, and enables researchers, for the first time, to conduct global-scale analyses covering large parts of our Earth using little computational resources. From a technical perspective, we provide a high-level parallel algorithm specification along with several performance-critical optimizations dedicated to efficiently map the specified parallelism to modern parallel devices. While a particular change detection method is addressed in this work, the algorithmic building blocks provided are also of immediate relevance to a wide variety of related approaches in remote sensing and other fields.
@inproceedings{GiesekeRHVO2020MassivelyParallel, author = {Gieseke, Fabian and Rosca, Sabina and Henriksen, Troels and Verbesselt, Jan and Oancea, Cosmin Eugen}, title = {Massively-Parallel Change Detection for Satellite Time Series Data with Missing Values}, booktitle = {Proceedings of the 36th {IEEE} International Conference on Data Engineering (ICDE)}, pages = {385--396}, year = {2020}, address = {Dallas, USA}, doi = {10.1109/ICDE48307.2020.00040}, tags = {de,rs}, } -
 C. E. Oancea, T. Robroek, and F. GiesekeIEEE BIGDATA 2020 2020 IEEE International Conference on Big Data 2020
C. E. Oancea, T. Robroek, and F. GiesekeIEEE BIGDATA 2020 2020 IEEE International Conference on Big Data 2020Nearest neighbour fields accurately and intuitively describe the transformation between two images and have been heavily used in computer vision. Generating such fields, however, is not an easy task due to the induced computational complexity, which quickly grows with the sizes of the images. Modern parallel devices such as graphics processing units depict a viable way of reducing the practical run time of such compute-intensive tasks. In this work, we propose a novel parallel implementation for one of the state-of-the-art methods for the computation of nearest neighbour fields, called p ropagation-assisted k -d trees. The resulting implementation yields valuable computational savings over a corresponding multi-core implementation. Additionally, it is tuned to consume only little additional memory and is, hence, capable of dealing with high-resolution image data, which is vital as image quality standards keep rising.
@inproceedings{OanceaRG2020Approximate, author = {Oancea, Cosmin Eugen and Robroek, Ties and Gieseke, Fabian}, title = {Approximate Nearest-Neighbour Fields via Massively-Parallel Propagation-Assisted K-D Trees}, booktitle = {2020 {IEEE} International Conference on Big Data}, pages = {5172--5181}, year = {2020}, publisher = {IEEE}, doi = {10.1109/BigData50022.2020.9378426}, tags = {de,ml}, } -
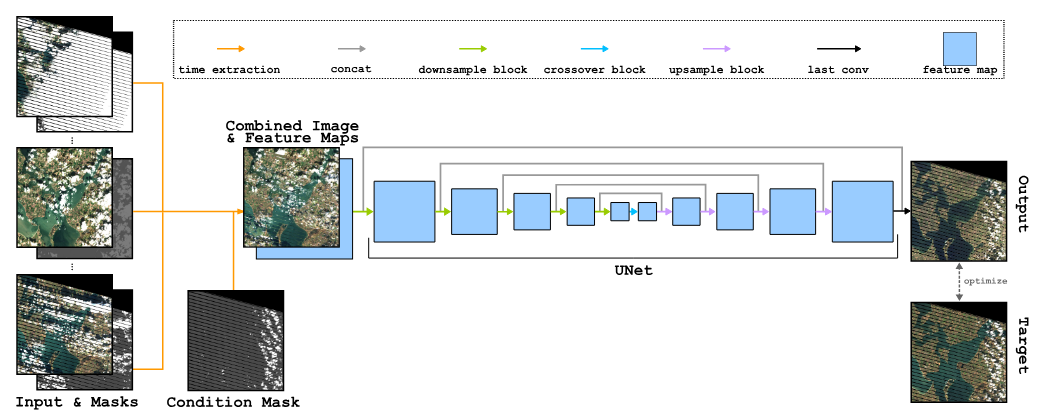 S. Oehmcke, T. K. Chen, A. V. Prishchepov, and F. GiesekeBIGSPATIAL20 Proceedings of the 9th ACM SIGSPATIAL International Workshop on Analytics for Big Geospatial Data 2020
S. Oehmcke, T. K. Chen, A. V. Prishchepov, and F. GiesekeBIGSPATIAL20 Proceedings of the 9th ACM SIGSPATIAL International Workshop on Analytics for Big Geospatial Data 2020Optical satellite images are important for environmental monitoring. Unfortunately, such images are often affected by distortions, such as clouds, shadows, or missing data. This work proposes a deep learning approach for cleaning and imputing satellite images, which could serve as a reliable preprocessing step for spatial and spatio-temporal analyzes. More specifically, a coherent and cloud-free image for a specific target date and region is created based on a sequence of images of that region obtained at previous dates. Our model first extracts information from the previous time steps via a special gating function and then resorts to a modified version of the well-known U-Net architecture to obtain the desired output image. The model uses supplementary data, namely the approximate cloud coverage of input images, the temporal distance to the target time, and a missing data mask for each input time step. During the training phase we condition our model with the targets cloud coverage and missing values (disabled in production), which allows us to use data afflicted by distortion during training and thus does not require pre-selection of distortion-free data. Our experimental evaluation, conducted on data of the Landsat missions, shows that our approach outperforms the commonly utilized approach that resorts to taking the median of cloud-free pixels for a given position. This is especially the case when the quality of the data for the considered period is poor (e.g., lack of cloud free-images during the winter/fall periods). Our deep learning approach allows to improve the utility of the entire Landsat archive, the only existing global medium-resolution free-access satellite archive dating back to the 1970s. It therefore holds scientific and societal potential for future analyses conducted on data from this and other satellite imagery repositories.
@inproceedings{OehmckeTHPG2020CreatingCloudFree, author = {Oehmcke, Stefan and Chen, Tzu-Hsin Karen and Prishchepov, Alexander V. and Gieseke, Fabian}, title = {Creating Cloud-Free Satellite Imagery from Image Time Series with Deep Learning}, booktitle = {Proceedings of the 9th ACM SIGSPATIAL International Workshop on Analytics for Big Geospatial Data}, pages = {3:1-3:10}, year = {2020}, publisher = {ACM}, address = {Seattle, USA}, doi = {10.1145/3423336.3429345}, tags = {ml,de,rs,application}, } -
 F. Gieseke, and C. IgelKDD18 Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD 2018, London, UK, August 19-23, 2018 2018
F. Gieseke, and C. IgelKDD18 Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD 2018, London, UK, August 19-23, 2018 2018Without access to large compute clusters, building random forests on large datasets is still a challenging problem. This is, in particular, the case if fully-grown trees are desired. We propose a simple yet effective framework that allows to efficiently construct ensembles of huge trees for hundreds of millions or even billions of training instances using a cheap desktop computer with commodity hardware. The basic idea is to consider a multi-level construction scheme, which builds top trees for small random subsets of the available data and which subsequently distributes all training instances to the top trees’ leaves for further processing. While being conceptually simple, the overall efficiency crucially depends on the particular implementation of the different phases. The practical merits of our approach are demonstrated using dense datasets with hundreds of millions of training instances.
@inproceedings{GiesekeI2018TrainingBig, author = {Gieseke, Fabian and Igel, Christian}, title = {Training Big Random Forests with Little Resources}, booktitle = {Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD 2018, London, UK, August 19-23, 2018}, pages = {1445--1454}, year = {2018}, publisher = {ACM}, doi = {10.1145/3219819.3220124}, tags = {ml,de}, } -
 F. Gieseke, C. E. Oancea, A. Mahabal, C. Igel, and T. HeskesHigh Performance Computing for Computational Science — VECPAR 2018 — 13th International Conference, São Pedro, Brazil, September 17-19, 2018, Revised Selected Papers 2018
F. Gieseke, C. E. Oancea, A. Mahabal, C. Igel, and T. HeskesHigh Performance Computing for Computational Science — VECPAR 2018 — 13th International Conference, São Pedro, Brazil, September 17-19, 2018, Revised Selected Papers 2018A buffer k-d tree is a k-d tree variant for massively-parallel nearest neighbor search. While providing valuable speed-ups on modern many-core devices in case both a large number of reference and query points are given, buffer k-d trees are limited by the amount of points that can fit on a single device. In this work, we show how to modify the original data structure and the associated workflow to make the overall approach capable of dealing with massive data sets. We further provide a simple yet efficient way of using multiple devices given in a single workstation. The applicability of the modified framework is demonstrated in the context of astronomy, a field that is faced with huge amounts of data.
@inproceedings{GiesekeOMIH2018BiggerBuffer, author = {Gieseke, Fabian and Oancea, Cosmin Eugen and Mahabal, Ashish and Igel, Christian and Heskes, Tom}, title = {Bigger Buffer k-d Trees on Multi-Many-Core Systems}, booktitle = {High Performance Computing for Computational Science --- VECPAR 2018 --- 13th International Conference, São Pedro, Brazil, September 17-19, 2018, Revised Selected Papers}, pages = {202--214}, series = {Lecture Notes in Computer Science}, volume = {11333}, year = {2018}, publisher = {Springer}, doi = {10.1007/978-3-030-15996-2\_15}, tags = {de}, } -
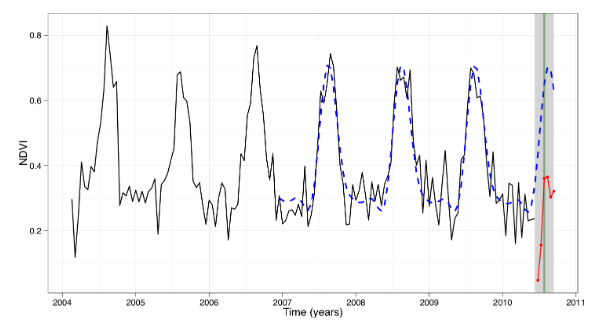 M. Mehren, F. Gieseke, J. Verbesselt, S. Rosca, S. Horion, and A. ZeileisProceedings of the 30th International Conference on Scientific and Statistical Database Management, SSDBM 2018, Bozen-Bolzano, Italy, July 09-11, 2018 2018
M. Mehren, F. Gieseke, J. Verbesselt, S. Rosca, S. Horion, and A. ZeileisProceedings of the 30th International Conference on Scientific and Statistical Database Management, SSDBM 2018, Bozen-Bolzano, Italy, July 09-11, 2018 2018The field of remote sensing is nowadays faced with huge amounts of data. While this offers a variety of exciting research opportunities, it also yields significant challenges regarding both computation time and space requirements. In practice, the sheer data volumes render existing approaches too slow for processing and analyzing all the available data. This work aims at accelerating BFAST, one of the state-of-the-art methods for break detection given satellite image time series. In particular, we propose a massively-parallel implementation for BFAST that can effectively make use of modern parallel compute devices such as GPUs. Our experimental evaluation shows that the proposed GPU implementation is up to four orders of magnitude faster than the existing publicly available implementation and up to ten times faster than a corresponding multi-threaded CPU execution. The dramatic decrease in running time renders the analysis of significantly larger datasets possible in seconds or minutes instead of hours or days. We demonstrate the practical benefits of our implementations given both artificial and real datasets.
@inproceedings{MehrenGVRHZ2018MassivelyParallel, author = {Mehren, Malte and Gieseke, Fabian and Verbesselt, Jan and Rosca, Sabine and Horion, Stefanie and Zeileis, Achim}, title = {Massively-parallel break detection for satellite data}, booktitle = {Proceedings of the 30th International Conference on Scientific and Statistical Database Management, SSDBM 2018, Bozen-Bolzano, Italy, July 09-11, 2018}, pages = {5:1-5:10}, year = {2018}, publisher = {ACM}, doi = {10.1145/3221269.3223032}, tags = {de}, } -
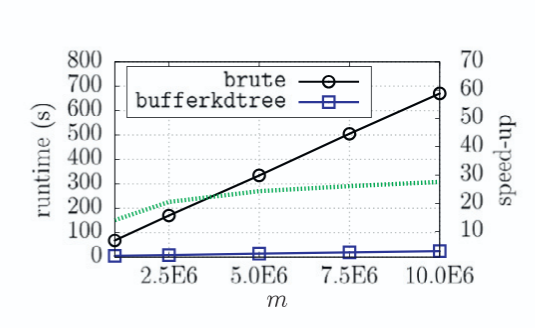 F. Gieseke, C. E. Oancea, and C. IgelKnowledge Based Systems 2017
F. Gieseke, C. E. Oancea, and C. IgelKnowledge Based Systems 2017The bufferkdtree package is an open-source software that provides an efficient implementation for processing huge amounts of nearest neighbor queries in Euclidean spaces of moderate dimensionality. Its underlying implementation resorts to a variant of the classical k-d tree data structure, called buffer k-d tree, which can be used to efficiently perform bulk nearest neighbor searches on modern many-core devices. The package, which is based on Python, C, and OpenCL, is made publicly available online at https://github.com/gieseke/bufferkdtree under the GPLv2 license.
@article{GiesekeOI17, author = {Gieseke, Fabian and Oancea, Cosmin E. and Igel, Christian}, title = {bufferkdtree: {A} Python library for massive nearest neighbor queries on multi-many-core devices}, journal = {Knowledge Based Systems}, volume = {120}, pages = {1--3}, year = {2017}, doi = {10.1016/j.knosys.2017.01.002}, tags = {de,hpc}, } -
 F. Gieseke, K. L. Polsterer, A. Mahabal, C. Igel, and T. Heskes2017 IEEE Symposium Series on Computational Intelligence, SSCI 2017, Honolulu, HI, USA, November 27 - Dec. 1, 2017 2017
F. Gieseke, K. L. Polsterer, A. Mahabal, C. Igel, and T. Heskes2017 IEEE Symposium Series on Computational Intelligence, SSCI 2017, Honolulu, HI, USA, November 27 - Dec. 1, 2017 2017Selecting an optimal subset of k out of d features for linear regression models given n training instances is often considered intractable for feature spaces with hundreds or thousands of dimensions. We propose an efficient massively-parallel implementation for selecting such optimal feature subsets in a brute-force fashion for small k. By exploiting the enormous compute power provided by modern parallel devices such as graphics processing units, it can deal with thousands of input dimensions even using standard commodity hardware only. We evaluate the practical runtime using artificial datasets and sketch the applicability of our framework in the context of astronomy.
@inproceedings{GiesekePMIH17, author = {Gieseke, Fabian and Polsterer, Kai Lars and Mahabal, Ashish and Igel, Christian and Heskes, Tom}, title = {Massively-parallel best subset selection for ordinary least-squares regression}, booktitle = {2017 {IEEE} Symposium Series on Computational Intelligence, {SSCI} 2017, Honolulu, HI, USA, November 27 - Dec. 1, 2017}, pages = {1--8}, publisher = {{IEEE}}, year = {2017}, doi = {10.1109/SSCI.2017.8285225}, tags = {de,ml}, } -
 K. L. Polsterer, F. Gieseke, C. Igel, B. Doser, and N. Gianniotis24th European Symposium on Artificial Neural Networks, ESANN 2016, Bruges, Belgium, April 27-29, 2016 2016
K. L. Polsterer, F. Gieseke, C. Igel, B. Doser, and N. Gianniotis24th European Symposium on Artificial Neural Networks, ESANN 2016, Bruges, Belgium, April 27-29, 2016 2016@inproceedings{PolstererGIDG16, author = {Polsterer, Kai Lars and Gieseke, Fabian and Igel, Christian and Doser, Bernd and Gianniotis, Nikolaos}, title = {Parallelized rotation and flipping INvariant Kohonen maps {(PINK)} on GPUs}, booktitle = {24th European Symposium on Artificial Neural Networks, {ESANN} 2016, Bruges, Belgium, April 27-29, 2016}, year = {2016}, tags = {de,application,hpc}, } -
 F. Gieseke, T. Pahikkala, and T. HeskesAdvances in Intelligent Data Analysis XIV - 14th International Symposium, IDA 2015, Saint Etienne, France, October 22-24, 2015, Proceedings 2015
F. Gieseke, T. Pahikkala, and T. HeskesAdvances in Intelligent Data Analysis XIV - 14th International Symposium, IDA 2015, Saint Etienne, France, October 22-24, 2015, Proceedings 2015The maximum margin clustering principle extends support vector machines to unsupervised scenarios. We present a variant of this clustering scheme that can be used in the context of interactive clustering scenarios. In particular, our approach permits the class ratios to be manually defined by the user during the fitting process. Our framework can be used at early stages of the data mining process when no or very little information is given about the true clusters and class ratios. One of the key contributions is an adapted steepest-descent-mildest-ascent optimization scheme that can be used to fine-tune maximum margin clustering solutions in an interactive manner. We demonstrate the applicability of our approach in the context of remote sensing and astronomy with training sets consisting of hundreds of thousands of patterns.
@inproceedings{GiesekePH15, author = {Gieseke, Fabian and Pahikkala, Tapio and Heskes, Tom}, editor = {{\'{E}}lisa Fromont and Bie, Tijl De and van Leeuwen, Matthijs}, title = {Batch Steepest-Descent-Mildest-Ascent for Interactive Maximum Margin Clustering}, booktitle = {Advances in Intelligent Data Analysis {XIV} - 14th International Symposium, {IDA} 2015, Saint Etienne, France, October 22-24, 2015, Proceedings}, series = {Lecture Notes in Computer Science}, volume = {9385}, pages = {95--107}, publisher = {Springer}, year = {2015}, doi = {10.1007/978-3-319-24465-5\_9}, tags = {de} } -
 T. Pahikkala, A. Airola, F. Gieseke, and O. KramerJournal of Computer Science and Technology (ICDM 2012 Special Issue) 2014
T. Pahikkala, A. Airola, F. Gieseke, and O. KramerJournal of Computer Science and Technology (ICDM 2012 Special Issue) 2014In this work we present the first efficient algorithm for unsupervised training of multi-class regularized least-squares classifiers. The approach is closely related to the unsupervised extension of the support vector machine classifier known as maximum margin clustering, which recently has received considerable attention, though mostly considering the binary classification case. We present a combinatorial search scheme that combines steepest descent strategies with powerful meta-heuristics for avoiding bad local optima. The regularized least-squares based formulation of the problem allows us to use matrix algebraic optimization enabling constant time checks for the intermediate candidate solutions during the search. Our experimental evaluation indicates the potential of the novel method and demonstrates its superior clustering performance over a variety of competing methods on real world datasets. Both time complexity analysis and experimental comparisons show that the method can scale well to practical sized problems.
@article{PahikkalaAGK14, author = {Pahikkala, Tapio and Airola, Antti and Gieseke, Fabian and Kramer, Oliver}, title = {On Unsupervised Training of Multi-Class Regularized Least-Squares Classifiers}, journal = {Journal of Computer Science and Technology (ICDM 2012 Special Issue)}, volume = {29}, number = {1}, pages = {90--104}, year = {2014}, doi = {10.1007/s11390-014-1414-0}, tags = {ml,de}, } -
 F. GiesekeKI 2013
F. GiesekeKI 2013Support vector machines are among the most popular techniques in machine learning. Given sufficient la- beled data, they often yield excellent results. However, for a variety of real-world tasks, the acquisition of sufficient la- beled data can be very time-consuming; unlabeled data, on the other hand, can often be obtained easily in huge quan- tities. Semi-supervised support vector machines try to take advantage of these additional unlabeled patterns and have been successfully applied in this context. However, they induce a hard combinatorial optimization problem. In this work, we present two optimization strategies that address this task and evaluate the potential of the resulting imple- mentations on real-world data sets, including an example from the field of astronomy.
@article{Gieseke13, author = {Gieseke, Fabian}, title = {From Supervised to Unsupervised Support Vector Machines and Applications in Astronomy}, journal = {{KI}}, volume = {27}, number = {3}, pages = {281--285}, year = {2013}, doi = {10.1007/s13218-013-0248-1}, tags = {ml,de,application}, } -
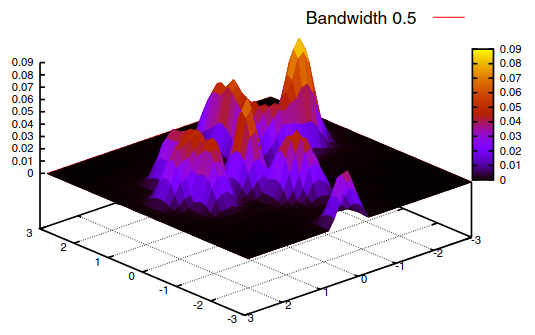 O. Kramer, and F. GiesekeExpert Systems with Applications 2012
O. Kramer, and F. GiesekeExpert Systems with Applications 2012The Nadaraya–Watson estimator, also known as kernel regression, is a density-based regression technique. It weights output values with the relative densities in input space. The density is measured with kernel functions that depend on bandwidth parameters. In this work we present an evolutionary bandwidth optimizer for kernel regression. The approach is based on a robust loss function, leave-one-out cross-validation, and the CMSA-ES as optimization engine. A variant with local parameterized Nadaraya–Watson models enhances the approach, and allows the adaptation of the model to local data space characteristics. The unsupervised counterpart of kernel regression is an approach to learn principal manifolds. The learning problem of unsupervised kernel regression (UKR) is based on optimizing the latent variables, which is a multimodal problem with many local optima. We propose an evolutionary framework for optimization of UKR based on scaling of initial local linear embedding solutions, and minimization of the cross-validation error. Both methods are analyzed experimentally.
@article{KramerG12, author = {Kramer, Oliver and Gieseke, Fabian}, title = {Evolutionary kernel density regression}, journal = {Expert Systems with Applications}, volume = {39}, number = {10}, pages = {9246--9254}, year = {2012}, doi = {10.1016/j.eswa.2012.02.080}, tags = {de}, } -
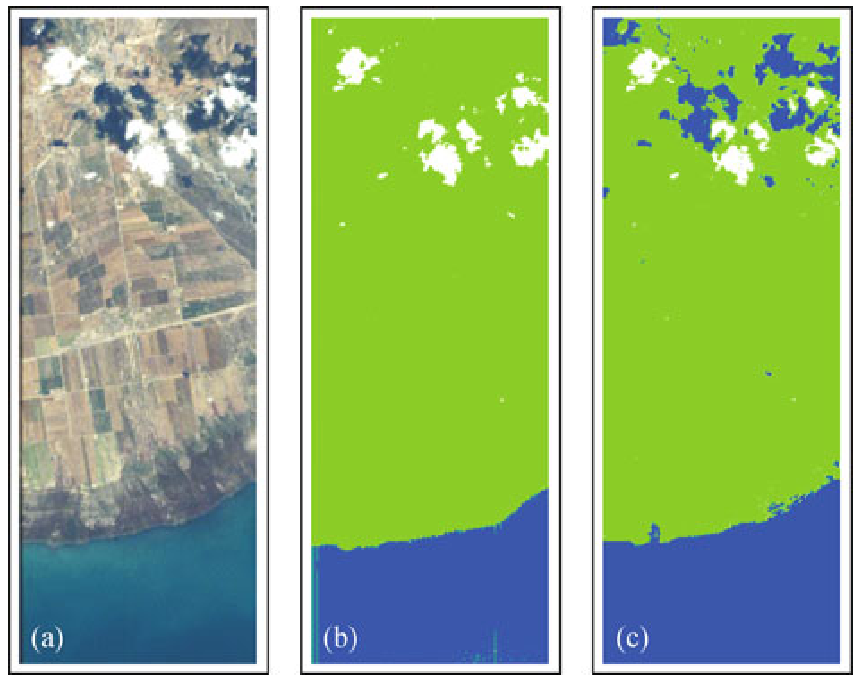 F. Gieseke, G. Moruz, and J. VahrenholdFrontiers of Computer Science (ICDM 2010 Special Issue) 2012
F. Gieseke, G. Moruz, and J. VahrenholdFrontiers of Computer Science (ICDM 2010 Special Issue) 2012We propose a k-d tree variant that is resilient to a pre-described number of memory corruptions while still using only linear space. While the data structure is of independent interest, we demonstrate its use in the context of high-radiation environments. Our experimental evaluation demonstrates that the resulting approach leads to a significantly higher resiliency rate compared to previous results. This is especially the case for large-scale multi-spectral satellite data, which renders the proposed approach well-suited to operate aboard today’s satellites.
@article{GiesekeMV12, author = {Gieseke, Fabian and Moruz, Gabriel and Vahrenhold, Jan}, title = {Resilient k-d trees: k-means in space revisited}, journal = {Frontiers of Computer Science (ICDM 2010 Special Issue)}, volume = {6}, number = {2}, pages = {166--178}, year = {2012}, doi = {10.1007/s11704-012-2870-8}, tags = {de} } -
 F. GiesekeAusgezeichnete Informatikdissertationen 2012 2012
F. GiesekeAusgezeichnete Informatikdissertationen 2012 2012Ein bekanntes Problem des maschinellen Lernens ist die Klassifikation von Objekten. Entsprechende Modelle basieren dabei meist auf Trainingsdaten, welche aus Mustern mit zugehörigen Labeln bestehen. Die Erstellung eines hinreichend großen Datensatzes kann sich für gewisse Anwendungsfälle jedoch als sehr kosten- oder zeitintensiv erweisen. Eine aktuelle Forschungsrichtung des maschinellen Lernens zielt auf die Verwendung von (zusätzlichen) ungelabelten Mustern ab, welche oft ohne großen Aufwand gewonnen werden können. In diesem Beitrag wird die Erweiterung von sogenannten Support-Vektor-Maschinen auf solche Lernszenarien beschrieben. Im Gegensatz zu Support-Vektor-Maschinen führen diese Varianten jedoch zu kombinatorischen Optimierungsproblemen. Die Entwicklung effizienter Optimierungsstrategien ist daher ein erstrebenswertes Ziel und soll im Rahmen dieses Beitrags diskutiert werden. Weiterhin werden mögliche Anwendungsgebiete der entsprechenden Verfahren erläutert, welche sich unter anderem im Bereich der Astronomie wiederfinden.
@inproceedings{Gieseke12, author = {Gieseke, Fabian}, editor = {H{\"{o}}lldobler, Steffen}, title = {Von {\"{u}}berwachten zu un{\"{u}}berwachten Support-Vektor-Maschinen und Anwendungen in der Astronomie}, booktitle = {Ausgezeichnete Informatikdissertationen 2012}, series = {{LNI}}, volume = {{D-13}}, pages = {111--120}, publisher = {{GI}}, year = {2012}, tags = {ml,de,application}, } -
 F. Giesekethesis Carl von Ossietzky University of Oldenburg 2011
F. Giesekethesis Carl von Ossietzky University of Oldenburg 2011A common task in the field of machine learning is the classification of objects. The basis for such a task is usually a training set consisting of patterns and associated class labels. A typical example is, for instance, the automatic classification of stars and galaxies in the field of astronomy. Here, the training set could consist of images and associated labels, which indicate whether a particular image shows a star or a galaxy. For such a learning scenario, one aims at generating models that can automatically classify new, unseen images. In the field of machine learning, various classification schemes have been proposed. One of the most popular ones is the concept of support vector machines, which often yields excellent classification results given sufficient labeled data. However, for a variety of real-world tasks, the acquisition of sufficient labeled data can be quite time-consuming. In contrast to labeled training data, unlabeled one can often be obtained easily in huge quantities. Semi- and unsupervised techniques aim at taking these unlabeled patterns into account to generate appropriate models. In the literature, various ways of extending support vector machines to these scenarios have been proposed. One of these ways leads to combinatorial optimization tasks that are difficult to address. In this thesis, several optimization strategies will be developed for these tasks that (1) aim at solving them exactly or (2) aim at obtaining (possibly suboptimal) candidate solutions in an efficient kind of way. More specifically, we will derive a polynomial-time approach that can compute exact solutions for special cases of both tasks. This approach is among the first ones that provide upper runtime bounds for the tasks at hand and, thus, yield theoretical insights into their computational complexity. In addition to this exact scheme, two heuristics tackling both problems will be provided. The first one is based on least-squares variants of the original tasks whereas the second one relies on differentiable surrogates for the corresponding objective functions. While direct implementations of both heuristics are still computationally expensive, we will show how to make use of matrix operations to speed up their execution. This will result in two optimization schemes that exhibit an excellent classification and runtime performance. Despite these theoretical derivations, we will also depict possible application domains of machine learning methods in astronomy. Here, the massive amount of data given for today’s and future projects renders a manual analysis impossible and necessitates the use of sophisticated techniques. In this context, we will derive an efficient way to preprocess spectroscopic data, which is based on an adaptation of support vector machines, and the benefits of semi-supervised learning schemes for appropriate learning tasks will be sketched. As a further contribution to this field, we will propose the use of so-called resilient algorithms for the automatic data analysis taking place aboard today’s spacecrafts and will demonstrate their benefits in the context of clustering hyperspectral image data.
@phdthesis{Gieseke2011, author = {Gieseke, Fabian}, title = {From supervised to unsupervised support vector machines and applications in astronomy}, school = {Carl von Ossietzky University of Oldenburg}, year = {2011}, tags = {ml,de,application} } -
 F. Gieseke, J. Gudmundsson, and J. VahrenholdJournal of Discrete Algorithms (JDA) 2010
F. Gieseke, J. Gudmundsson, and J. VahrenholdJournal of Discrete Algorithms (JDA) 2010Given a geometric graph G = (S, E) in Rd with constant dilation t, and a positive constant ε, we show how to construct a (1 + ε )-spanner of G with O(|S|) edges using O(sort(|E|)) memory transfers in the cache-oblivious model of computation. The main building block of our algorithm, and of independent interest in itself, is a new cache- oblivious algorithm for constructing a well-separated pair decomposition which builds such a data structure for a given point set S ⊂ Rd using O(sort(|S|)) memory transfers.
@article{GiesekeGV10, author = {Gieseke, Fabian and Gudmundsson, Joachim and Vahrenhold, Jan}, title = {Pruning spanners and constructing well-separated pair decompositions in the presence of memory hierarchies}, journal = {Journal of Discrete Algorithms (JDA)}, volume = {8}, number = {3}, pages = {259--272}, year = {2010}, url = {https://doi.org/10.1016/j.jda.2010.03.001}, doi = {10.1016/j.jda.2010.03.001}, tags = {de}, } -
 F. Gieseke, G. Moruz, and J. VahrenholdICDM10 ICDM 2010, The 10th IEEE International Conference on Data Mining, Sydney, Australia, 14-17 December 2010 2010
F. Gieseke, G. Moruz, and J. VahrenholdICDM10 ICDM 2010, The 10th IEEE International Conference on Data Mining, Sydney, Australia, 14-17 December 2010 2010We develop a k-d tree variant that is resilient to a pre-described number of memory corruptions while still using only linear space. We show how to use this data structure in the context of clustering in high-radiation environments and demonstrate that our approach leads to a significantly higher resiliency rate compared to previous results.
@inproceedings{GiesekeMV10, author = {Gieseke, Fabian and Moruz, Gabriel and Vahrenhold, Jan}, editor = {Webb, Geoffrey I. and Liu, Bing and Zhang, Chengqi and Gunopulos, Dimitrios and Wu, Xindong}, title = {Resilient K-d Trees: K-Means in Space Revisited}, booktitle = {{ICDM} 2010, The 10th {IEEE} International Conference on Data Mining, Sydney, Australia, 14-17 December 2010}, pages = {815--820}, publisher = {{IEEE} Computer Society}, year = {2010}, doi = {10.1109/ICDM.2010.94}, tags = {de}, } -
 F. Gieseke, and J. VahrenholdProceedings of the 25th European Workshop on Computational Geometry 2009
F. Gieseke, and J. VahrenholdProceedings of the 25th European Workshop on Computational Geometry 2009We present a cache-oblivious algorithm for computing a well-separated pair decomposition of a finite point set S ⊂ Rd using O(sort(|S|)) memory transfers.
@inproceedings{GiesekeV2009, author = {Gieseke, Fabian and Vahrenhold, Jan}, title = {Cache-Oblivious Construction of a Well-Separated Pair Decomposition}, booktitle = {Proceedings of the 25th European Workshop on Computational Geometry}, year = {2009}, pages = {341-344}, tags = {de}, }

























